PyTorch
本文记录并行计算与神经网络库 PyTorch 的基本用法。
PyTorch 安装¶
默认大家对 CPU 体系 有一定的了解,那么从 CPU 过渡到 GPU 就有迹可循了:
| 层级 | CPU | GPU |
|---|---|---|
| 硬件 | CPU (x86/ARM) | GPU (NVIDIA) |
| 驱动 | OS Kernel | NVIDIA Driver |
| 工具链 | GCC | CUDA Toolkit |
| 高性能算子库 | MKL / OpenBLAS | cuDNN |
| Python 包 | NumPy、PyTorch (CPU) | PyTorch (CUDA) |
上表从上到下本质上是逐层封装的过程。
快速上手¶
首先安装 NVIDIA Driver 和 CUDA Toolkit。
接着安装高性能算子库和 torch 包。torch 包会自动安装算子库,所以只需要安装 torch 包即可。以 torch==2.8.0 版本为例,其余版本请前往 PyTorch 官网 查看:
# ROCM 6.4 (Linux only)
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/rocm6.4
# CUDA 12.6
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu126
# CUDA 12.8
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
# CUDA 12.9
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu129
# CPU only
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cpu
版本兼容¶
依赖链一长,兼容性就显得格外脆弱,从上游到下游(驱动、编译器、包)的依赖情况如下。
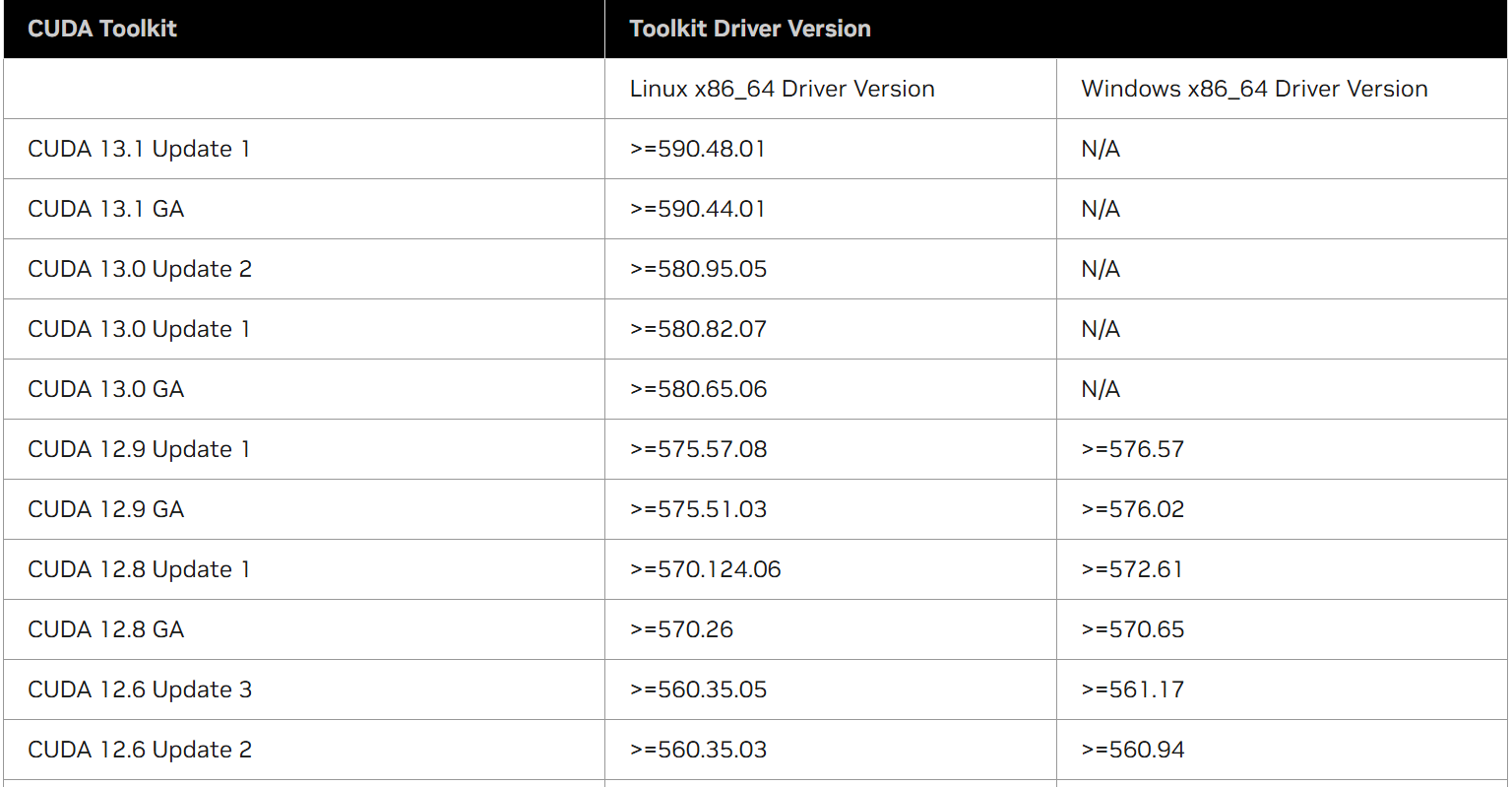
查看 CUDA 版本:
查看 NVIDIA Driver 版本:
CUDA 与 GCC 的兼容矩阵(CUDA 依赖 GCC 的一些库):
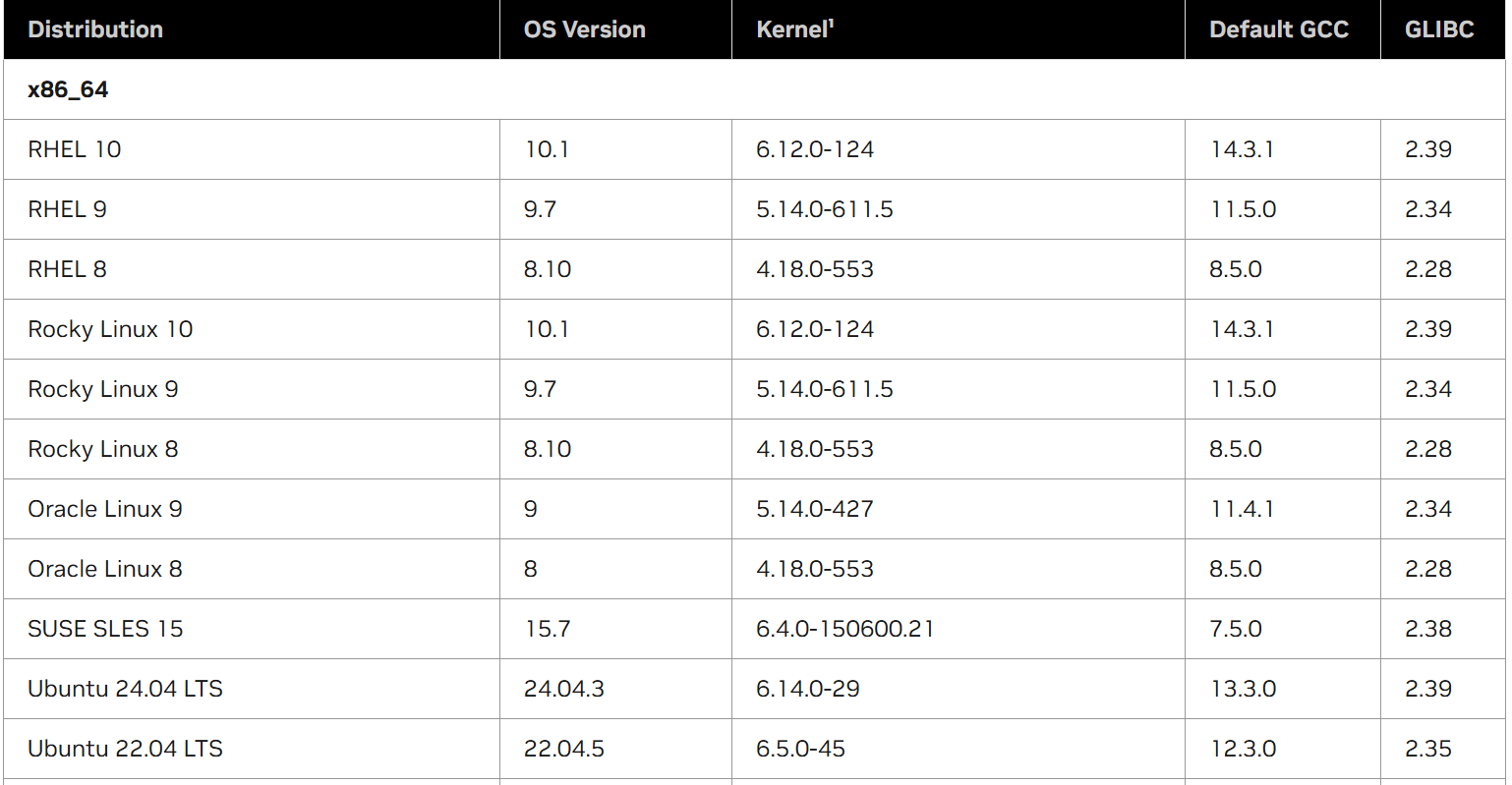
查看 GCC 版本:
CUDA 与 PyTorch 和 Python 的兼容矩阵:
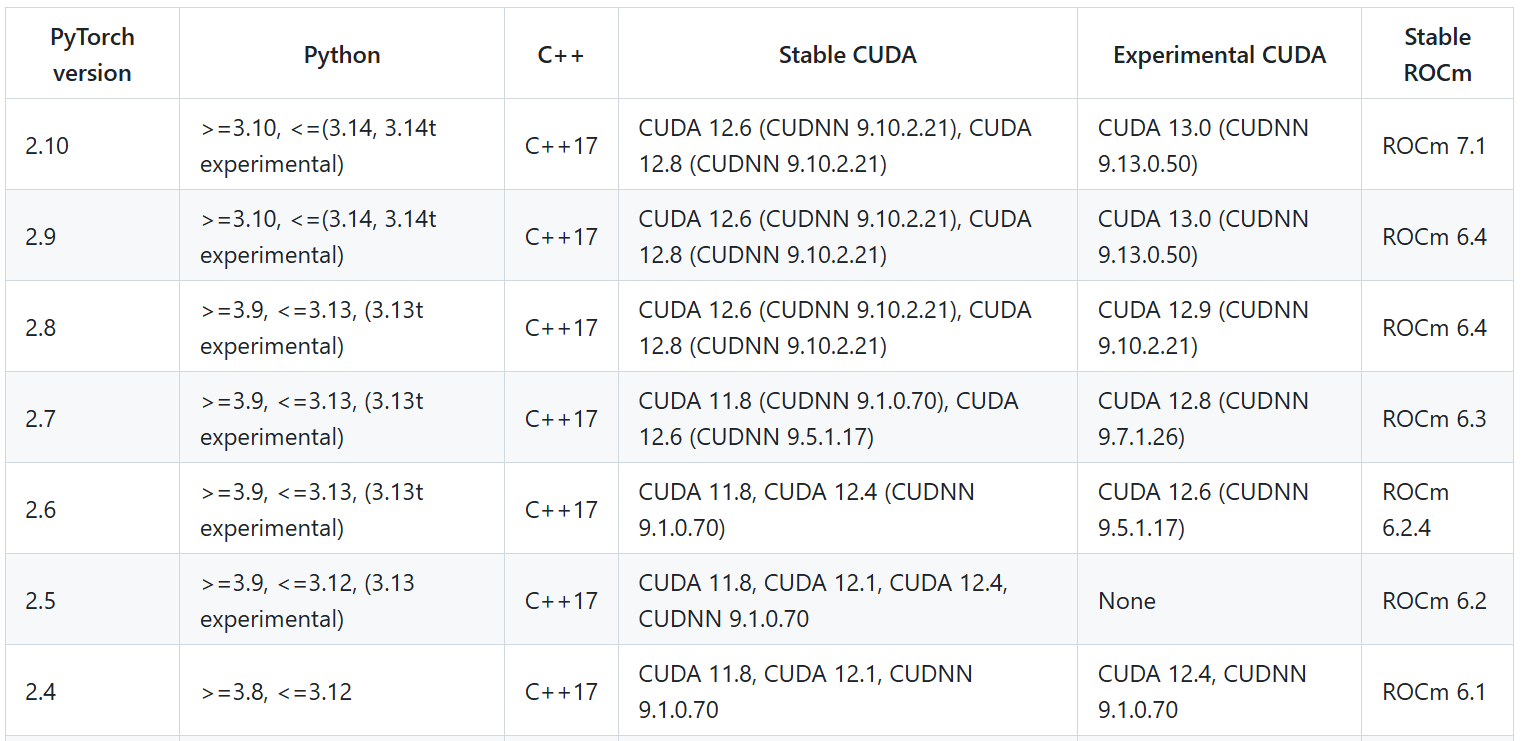
查看 Python 版本:
查看 PyTorch 版本:
数据类型¶
PyTorch 的数据类型被称为张量 (tensor),可以表示任意维度的向量。
张量创建¶
import numpy as np
import torch
# 从 Python 列表创建
x = torch.tensor([1, 2, 3])
# 从 NumPy 数组创建
np_array = np.array([1, 2, 3])
x_from_np = torch.from_numpy(np_array)
# 创建特殊张量
zeros = torch.zeros(2, 3) # 全零张量
ones = torch.ones(2, 3) # 全一张量
rand = torch.rand(2, 3) # [0, 1) 均匀分布
randn = torch.randn(2, 3) # 标准正态分布
# 创建指定数据类型的张量
x_float = torch.tensor([1, 2, 3], dtype=torch.float32)
x_long = torch.tensor([1, 2, 3], dtype=torch.long)
# 创建与现有张量相同形状的张量
x = torch.randn(2, 3)
y = torch.zeros_like(x)
张量属性¶
x = torch.randn(2, 3, 4)
print(x.shape) # torch.Size([2, 3, 4])
print(x.size()) # torch.Size([2, 3, 4])
print(x.dtype) # torch.float32
print(x.device) # cpu 或 cuda:0
print(x.numel()) # 24 (元素总数)
print(x.dim()) # 3 (维度数)
张量操作¶
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
# 基本运算
z = x + y # 逐元素加法
z = torch.add(x, y) # 逐元素加法(函数形式)
x.add_(y) # 原地加法(会修改 x)
z = x * y # 逐元素乘法
z = x @ y # 点积/内积
z = x.dot(y) # 点积/内积(函数形式)
# 矩阵运算
A = torch.randn(2, 3)
B = torch.randn(3, 4)
C = A @ B # 矩阵乘法
C = torch.matmul(A, B) # 矩阵乘法(函数形式)
# 形状变换
x = torch.randn(2, 3, 4)
y = x.view(2, 12) # 重塑形状,新形状 (2, 12)
y = x.reshape(2, -1) # 重塑形状,新形状 (2, 12)(-1 表示自动推断维度)
y = x.transpose(0, 1) # 交换维度,新形状 (3, 2, 4)
y = x.permute(2, 0, 1) # 重排维度,新形状 (4, 2, 3)
# 索引和切片
x = torch.randn(4, 5)
print(x[0]) # 第一行
print(x[:, 1]) # 第二列
print(x[1:3, :]) # 第 2-3 行
# 拼接
x = torch.randn(2, 3)
y = torch.randn(2, 3)
z = torch.cat([x, y], dim=0) # 沿指定维度拼接,新形状 (4, 3)
z = torch.stack([x, y], dim=0) # 插入一个新维度,新形状 (2, 2, 3)
torch.view() 和 torch.reshape() 的区别
torch.view(): 若内存连续,则共享内存;否则报错。torch.reshape(): 若内存连续,则共享内存;否则会先调用.contiguous()自动复制一份。
自动微分¶
3.1 基本用法¶
# 创建需要梯度的张量
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2 + 3 * x + 1
# 计算梯度
y.backward()
print(x.grad) # tensor([7.]) (dy/dx = 2x + 3 = 7)
# 梯度累积(默认行为)
x = torch.tensor([2.0], requires_grad=True)
for i in range(3):
y = x ** 2
y.backward()
print(x.grad) # 梯度会累积
# 清零梯度
x.grad.zero_()
3.2 复杂计算图¶
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
# 对非标量进行反向传播需要提供 gradient 参数
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)
print(x.grad)
3.3 控制梯度计算¶
# 临时禁用梯度计算
x = torch.randn(3, requires_grad=True)
with torch.no_grad():
y = x * 2 # y 不会追踪梯度
# 使用 @torch.no_grad() 装饰器
@torch.no_grad()
def inference(model, x):
return model(x)
# 分离张量(创建不需要梯度的副本)
x = torch.randn(3, requires_grad=True)
y = x.detach() # y 与 x 共享数据但不追踪梯度
数据处理¶
6.1 Dataset 和 DataLoader¶
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, data, labels, transform=None):
self.data = data
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
label = self.labels[idx]
if self.transform:
sample = self.transform(sample)
return sample, label
# 使用
dataset = CustomDataset(X_train, y_train)
dataloader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4, # 多进程加载
pin_memory=True # 加速 CPU 到 GPU 传输
)
6.2 图像数据增强¶
from torchvision import transforms
# 定义变换
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 应用到数据集
from torchvision.datasets import ImageFolder
train_dataset = ImageFolder(root='train/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
6.3 内置数据集¶
from torchvision import datasets, transforms
# MNIST
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
# CIFAR-10
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
网络构建¶
4.1 使用 nn.Module 构建网络¶
import torch.nn as nn
import torch.nn.functional as F
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 展平
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = SimpleNet()
print(model)
# 查看参数
for name, param in model.named_parameters():
print(f"{name}: {param.shape}")
4.2 常用层¶
# 全连接层
fc = nn.Linear(in_features=100, out_features=10)
# 卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
conv1d = nn.Conv1d(in_channels=10, out_channels=20, kernel_size=5)
# 池化层
maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应池化
# 归一化层
bn = nn.BatchNorm2d(64)
ln = nn.LayerNorm(128)
# Dropout
dropout = nn.Dropout(p=0.5)
# 激活函数
relu = nn.ReLU()
sigmoid = nn.Sigmoid()
tanh = nn.Tanh()
4.3 卷积神经网络示例¶
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # (28, 28) -> (14, 14)
x = self.pool(F.relu(self.conv2(x))) # (14, 14) -> (7, 7)
x = x.view(-1, 64 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
model = CNN()
4.4 Sequential 容器¶
# 使用 Sequential 简化模型定义
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 10)
)
# 使用 OrderedDict 命名层
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
训练流程¶
5.1 完整训练示例¶
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 1. 准备数据
X_train = torch.randn(1000, 10)
y_train = torch.randint(0, 2, (1000,))
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 2. 定义模型
model = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 2)
)
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4. 训练循环
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 设置为训练模式
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 前向传播
outputs = model(data)
loss = criterion(outputs, target)
# 反向传播
optimizer.zero_grad() # 清零梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}")
5.2 验证和测试¶
def evaluate(model, data_loader, criterion, device):
model.eval() # 设置为评估模式
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算
for data, target in data_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
loss = criterion(outputs, target)
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
avg_loss = total_loss / len(data_loader)
accuracy = 100 * correct / total
return avg_loss, accuracy
# 使用
val_loss, val_acc = evaluate(model, val_loader, criterion, device)
print(f"Validation Loss: {val_loss:.4f}, Accuracy: {val_acc:.2f}%")
5.3 学习率调度¶
# 阶梯式学习率衰减
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 余弦退火
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)
# 根据验证指标调整
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=3
)
# 训练循环中使用
for epoch in range(num_epochs):
train_one_epoch()
val_loss = validate()
# StepLR 或 CosineAnnealingLR
scheduler.step()
# ReduceLROnPlateau
scheduler.step(val_loss)
CPU \(\to\) GPU¶
# 检查 CUDA 是否可用
print(torch.cuda.is_available())
# 设置默认设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将张量移动到 GPU
x = torch.randn(2, 3)
x_gpu = x.to(device)
x_gpu = x.cuda() # 简写形式
# 在 GPU 上直接创建张量
x_gpu = torch.randn(2, 3, device=device)
# 将张量移回 CPU
x_cpu = x_gpu.cpu()
七、模型保存与加载¶
7.1 保存和加载整个模型¶
7.2 保存和加载模型参数(推荐)¶
# 保存
torch.save(model.state_dict(), 'model_params.pth')
# 加载
model = SimpleNet() # 需要先实例化模型
model.load_state_dict(torch.load('model_params.pth'))
model.eval()
7.3 保存训练检查点¶
# 保存
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}
torch.save(checkpoint, 'checkpoint.pth')
# 加载并继续训练
checkpoint = torch.load('checkpoint.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.train()
八、高级技巧¶
8.1 混合精度训练¶
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for epoch in range(num_epochs):
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 自动混合精度
with autocast():
outputs = model(data)
loss = criterion(outputs, target)
# 梯度缩放
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
8.2 梯度裁剪¶
# 训练循环中
loss.backward()
# 裁剪梯度范数
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 或裁剪梯度值
torch.nn.utils.clip_grad_value_(model.parameters(), clip_value=0.5)
optimizer.step()
8.3 模型融合(Ensemble)¶
class EnsembleModel(nn.Module):
def __init__(self, models):
super(EnsembleModel, self).__init__()
self.models = nn.ModuleList(models)
def forward(self, x):
predictions = [model(x) for model in self.models]
# 平均预测结果
return torch.stack(predictions).mean(dim=0)
# 使用
model1 = CNN()
model2 = CNN()
model3 = CNN()
ensemble = EnsembleModel([model1, model2, model3])
8.4 自定义损失函数¶
class CustomLoss(nn.Module):
def __init__(self, weight=1.0):
super(CustomLoss, self).__init__()
self.weight = weight
def forward(self, predictions, targets):
mse_loss = F.mse_loss(predictions, targets)
l1_loss = F.l1_loss(predictions, targets)
return mse_loss + self.weight * l1_loss
criterion = CustomLoss(weight=0.5)
分布式¶
在深度学习模型日益庞大的今天,单卡往往显得力不从心。PyTorch 提供了强大的分布式支持,旨在解决这一问题。
基本概念¶
分布式本质上是多个进程之间的协同工作,有以下几个常见的术语:
- 节点 (Node):物理主机。比如你有一台服务器,它就是一个 Node;如果有两台服务器互联,就是两个 Nodes;
- 总进程数 (World Size):全局的总进程数。通常情况下,World Size = Node 数量 \(\times\) 每个 Node 的 GPU 数量;
- 全局进程号 (Rank):整个分布式任务中的进程唯一序号(0 到 World Size - 1)。Rank 0 通常被称为主进程(Master),负责协调工作。
- 本地进程号 (Local Rank):当前节点内的进程唯一序号。例如单机 8 卡,Local Rank 就是 0-7;
- 进程组 (Process Group):进程的子集。默认情况下,所有进程都在一个默认组中,但也可以创建子组进行特定的通信。
分布式离不开进程间通信。PyTorch 底层主要依赖以下几种通信模式:
- Broadcast:将数据从一个节点广播到所有其他节点;
- Scatter 与 Gather:将数据切分分发给各节点,以及从各节点收集数据拼凑在一起;
- All-Reduce:所有节点的数据进行规约(如求和、平均),并将结果返回给所有节点。在梯度更新中,我们依靠它来同步各卡的梯度。
分布式策略:
- 数据并行 (Data Parallelism, DP)。模型在每张卡上都有一份副本,数据被切分,每张卡处理不同的数据,最后同步梯度;
- 张量并行。
分布式启动方式:
之后可以加载分布式的环境变量,例如:
rank = int(os.getenv("RANK", 0))
local_rank = int(os.getenv("LOCAL_RANK", 0))
world_size = int(os.getenv("WORLD_SIZE", 1))
使用 torchrun 启动多进程后,如果未显式设置 OMP_NUM_THREADS,PyTorch 会为了避免 CPU 过载,自动将其设为 1,并打印如下警告:
W1114 17:59:52.294000 3097815 torch/distributed/run.py:774] *****************************************
W1114 17:59:52.294000 3097815 torch/distributed/run.py:774] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
W1114 17:59:52.294000 3097815 torch/distributed/run.py:774] *****************************************
OMP_NUM_THREADS 是 OpenMP 的标准环境变量。由于 PyTorch 底层的很多 CPU 算子(比如矩阵乘法、卷积等)是基于 OpenMP 实现并行的,这个变量决定了:每个进程在执行这些算子时可以使用的线程数。
可以在终端启动时设置(最推荐)
也可以在 Python 脚本顶部设置:
参数大小的设置视情况而定:
| 场景 | 推荐值 | 理由 |
|---|---|---|
| 常规分布式场景 | 1 或 2 | 绝大多数深度学习任务的瓶颈在 GPU,CPU 主要负责 Data Loading。设置较小的值可以减少线程竞争。 |
| 数据增强复杂 | 4 或 8 | 如果你的 DataLoader 中 num_workers 较多,或者有复杂的 CPU 计算,可以适当增加。 |
| CPU 训练 | 核心总数 | 只有在纯 CPU 训练且单进程时才设为最大。 |
DP¶
数据并行 (DataParallel, DP) 是 PyTorch 早期提供的「单机多卡」数据并行方案。它基于单进程多线程,主 GPU 负责分发数据、收集输出、计算 Loss 并分发梯度。由于 Python GIL 限制了多线程的效率,且主 GPU 负载过重导致显存负载不均衡,目前已不推荐用于生产环境。
简单的数据并行:
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 个 GPU")
model = nn.DataParallel(model)
model.to(device)
DDP¶
分布式数据并行 (DistributedDataParallel, DDP) 是目前最通用的方案,不仅可以「单机多卡」,还可以「多机多卡」。它给每个 GPU 单独启动一个进程,规避了 GIL 限制,速度更快。同时采用环状通信 (Ring All-Reduce) 算法,让所有 GPU 协同同步梯度,没有中心瓶颈,显存占用更均衡。
示例程序:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from models import YourModel
def train_ddp(local_rank, rank, world_size):
# ==============================
# 初始化分布式环境
# ==============================
# 将当前进程绑定到对应的 GPU
torch.cuda.set_device(local_rank)
# 初始化进程组,确定数据通信方式
dist.init_process_group(
backend="nccl", # GPU 间的通信后端
init_method="env://", # 从环境变量中读取地址端口信息,如 MASTER_ADDR, MASTER_PORT
rank=rank, # 全局进程编号
world_size=world_size # 总进程数
)
# ==============================
# 训练一条龙:数据 & 模型 & 损失
# ==============================
# dataloader
from torch.utils.data.distributed import DistributedSampler
sampler = DistributedSampler(train_dataset, num_replicas=world_size, rank=rank)
train_loader = DataLoader(train_dataset, batch_size=32, sampler=sampler)
# model
model = YourModel().to(rank)
model = DDP(model, device_ids=[rank])
# loss
for epoch in range(num_epochs):
sampler.set_epoch(epoch) # 打乱数据
for data, target in train_loader:
pass
# ==============================
# 销毁分布式环境
# ==============================
# 等待当前设备上的所有 CUDA 任务都执行完(针对当前进程对 CUDA 的异步调用)
torch.cuda.synchronize()
# 确保所有进程都到达当前位置(针对所有进程的分布式策略)
dist.barrier()
# 销毁进程组(针对所有进程的分布式策略)
dist.destroy_process_group()
FSDP¶
当模型参数大到单张显卡(甚至单机)都放不下时,DDP 就无能为力了,因为 DDP 要求每张卡都必须存储一份完整的模型参数。这时我们需要 FSDP (Fully Sharded Data Parallel)。
FSDP 的核心思想是「切分一切」,除了数据,优化器状态、梯度,甚至模型都能切。它源自微软的 ZeRO (Zero Redundancy Optimizer) 理念。当然代价就是数据通信时延增加了,这是没办法的事情(时间换空间)。
十、调试与性能优化¶
10.1 检测异常值¶
# 启用异常检测
torch.autograd.set_detect_anomaly(True)
# 检查 NaN 和 Inf
def check_nan_inf(tensor, name="tensor"):
if torch.isnan(tensor).any():
print(f"{name} contains NaN")
if torch.isinf(tensor).any():
print(f"{name} contains Inf")
10.2 性能分析¶
from torch.profiler import profile, ProfilerActivity
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for i in range(10):
output = model(input_data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
10.3 内存优化¶
# 使用 checkpoint 减少内存占用(牺牲速度)
from torch.utils.checkpoint import checkpoint
class MyModel(nn.Module):
def forward(self, x):
# 使用 checkpoint 包装计算密集的部分
x = checkpoint(self.heavy_computation, x)
return x
# 及时释放不需要的张量
del large_tensor
torch.cuda.empty_cache()
十一、实用工具¶
11.1 TensorBoard 可视化¶
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('runs/experiment_1')
for epoch in range(num_epochs):
# 训练
train_loss = train_one_epoch()
val_loss, val_acc = validate()
# 记录标量
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Loss/val', val_loss, epoch)
writer.add_scalar('Accuracy/val', val_acc, epoch)
# 记录模型图
if epoch == 0:
writer.add_graph(model, input_data)
# 记录图像
writer.add_images('predictions', img_grid, epoch)
writer.close()
# 启动 TensorBoard: tensorboard --logdir=runs
11.2 随机种子设置¶
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
import random
random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
11.3 模型参数统计¶
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"模型参数量: {count_parameters(model):,}")
# 查看每层参数
for name, param in model.named_parameters():
print(f"{name}: {param.numel():,} 参数")
查看系统信息¶
指定可见 GPU¶
让系统只关注特定的显卡:
假设一机八卡,此时 torch 只会找到其中编号为 0 和 1 的卡。
十二、常见问题与解决方案¶
12.1 内存不足(OOM)¶
# 减小 batch size
batch_size = 16 # 从 32 减少到 16
# 使用梯度累积模拟大 batch
accumulation_steps = 4
# 使用混合精度训练
from torch.cuda.amp import autocast, GradScaler
# 释放缓存
torch.cuda.empty_cache()
12.2 训练不收敛¶
# 检查学习率
optimizer = optim.Adam(model.parameters(), lr=1e-4) # 降低学习率
# 添加梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 检查损失函数
print(f"Loss: {loss.item()}") # 监控损失值
# 使用学习率预热
def warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor):
def f(x):
if x >= warmup_iters:
return 1
alpha = float(x) / warmup_iters
return warmup_factor * (1 - alpha) + alpha
return torch.optim.lr_scheduler.LambdaLR(optimizer, f)
12.3 过拟合¶
# 添加 Dropout
model.add_module('dropout', nn.Dropout(0.5))
# 使用数据增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor()
])
# 添加权重衰减(L2 正则化)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
# 早停
class EarlyStopping:
def __init__(self, patience=7, delta=0):
self.patience = patience
self.counter = 0
self.best_loss = None
self.delta = delta
def __call__(self, val_loss):
if self.best_loss is None:
self.best_loss = val_loss
elif val_loss > self.best_loss - self.delta:
self.counter += 1
if self.counter >= self.patience:
return True
else:
self.best_loss = val_loss
self.counter = 0
return False