文本生成(机器翻译)
现代文本生成任务包括翻译、摘要、问答、对话等,而机器翻译 (Machine Translation , MT) 是最典型的序列到序列建模场景。本文以机器翻译为切入点,从传统统计方法过渡到神经网络方法,并系统介绍序列到序列 (Sequence to Sequence, Seq2Seq) 与注意力 (Attention) 机制,为后续理解 Transformer 奠定基础。
基本概念¶
任务定义¶
机器翻译的目标是:给定源语言序列,将其映射为目标语言序列,是一个条件生成问题:
数据集¶
常用数据集包括 WMT 系列。以 WMT19 ZH-EN 为例,其中训练集约 26M、验证集约 4K,示例如下:
| JSON | |
|---|---|
评价方法¶
- BLEU:基于 n-gram 精确度的翻译质量指标;
- ROUGE:更偏向召回,用于摘要,但翻译中也可参考。
传统方法——统计机器翻译¶
统计机器翻译 (SMT) 将翻译分解为:
其中 \(p(x\mid y)\) 表示反向翻译模型,\(p(y)\) 表示语言模型。
缺点在于组件繁多、规则繁重、难以扩展。
Seq2Seq 架构¶
Seq2Seq 通过 Encoder-Decoder 模型直接建模 \(p(y \mid x)\)。使用 RNN (LSTM/GRU) 实现。
参考论文:Effective Approaches to Attention-based Neural Machine Translation
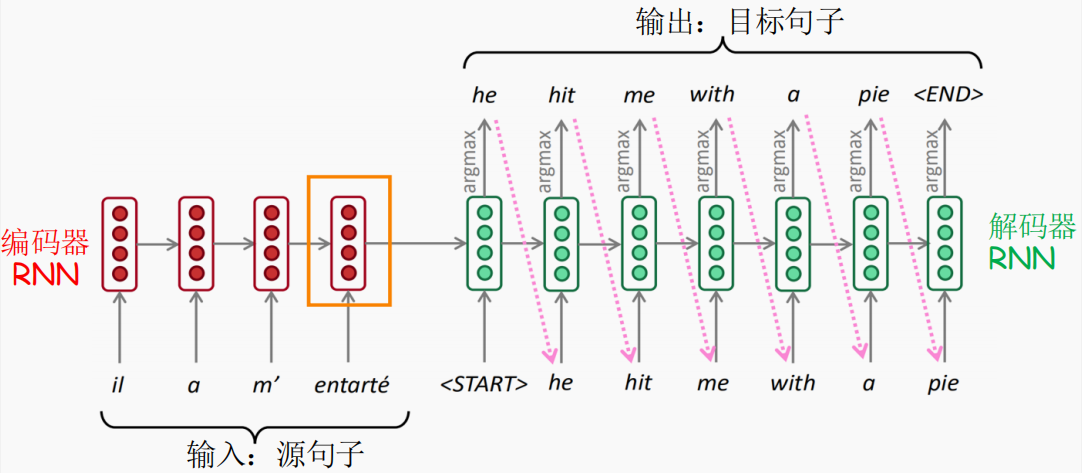
Encoder¶
将输入序列逐步编码为隐藏状态序列,早期模型仅使用最终状态作为整体语义压缩。
Decoder 与自回归生成¶
Decoder 在每个时间步预测:
训练与推理不同:
- 训练 (Teacher Forcing):使用真实 token;
- 测试:使用上一步模型预测,完全自回归。
为了避免贪心选择的局限,使用 beam search 扩展搜索空间。
Attention 机制¶
在 RNN seq2seq 中加入 Attention 后结构如下:
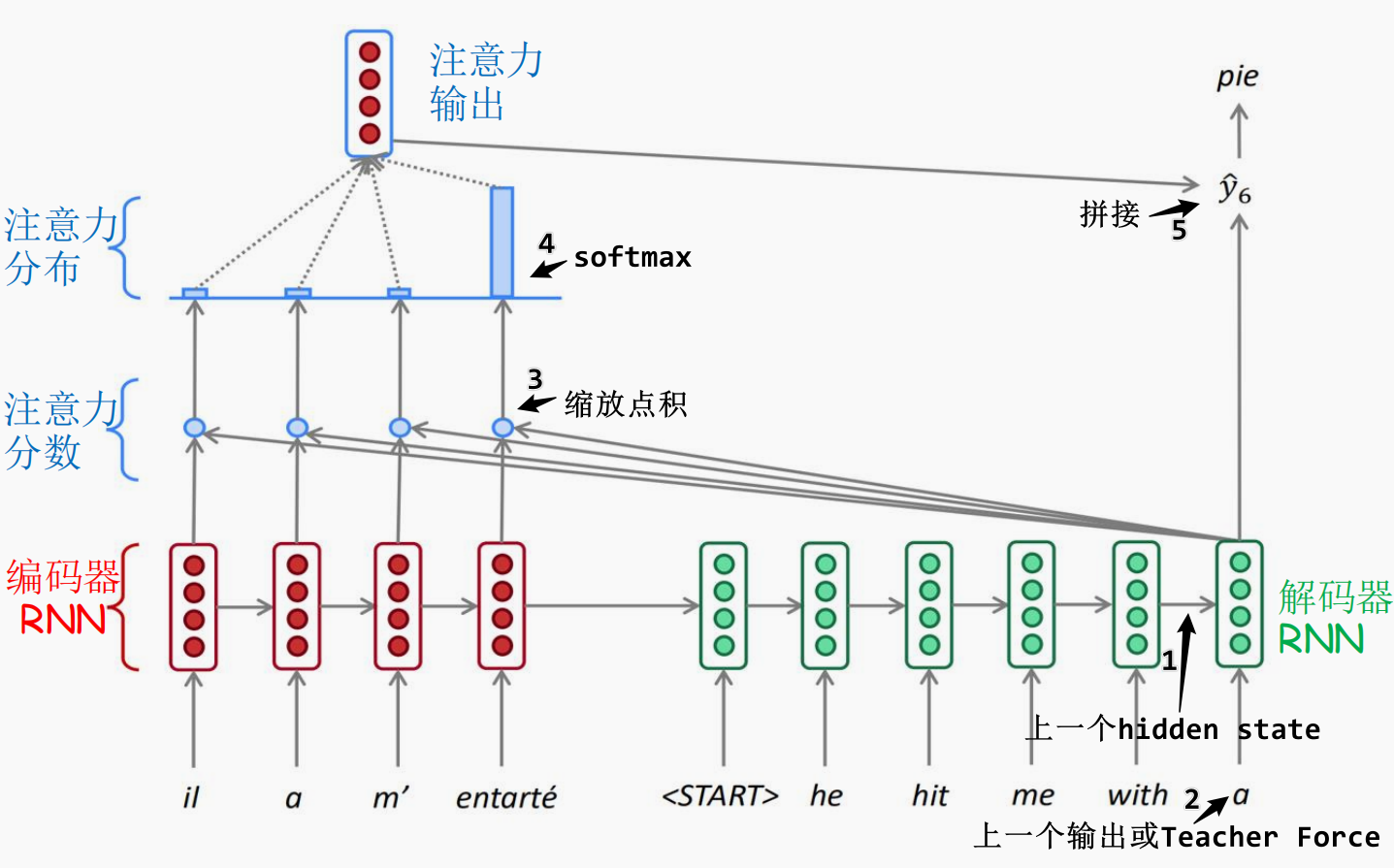
机制说明¶
步骤:
- 将 Encoder 所有隐藏状态作为 values(亦作为 keys);
- Decoder 当前隐藏状态作为 query;
- 计算注意力权重(缩放点积注意力);
- 对 values 加权求和,得到上下文向量。
Attention 的意义:
- 缓解信息瓶颈
- 模型可解释,通过注意力矩阵建立“软对齐”
如果输入序列很长,需改进注意力的计算方式以适配大规模场景。
总结与展望¶
基于 RNN 的优缺点:
- 缺点:长依赖困难、可解释性弱、难并行、曝光偏差
- 优点:自回归模式自然与训练接口一致
Attention 提升了 RNN 的训练效率与表达能力,但 RNN 本身的串行结构仍然无法并行。
完全并行化的 Transformer 由 Attention 推广而来,感兴趣的读者可移步 Transformer 作进一步阅读。