文本分类
文本分类常见的任务包括依存分析、命名实体识别与情感识别。三类任务覆盖句法、序列标签与语义判断等不同层面的语言处理目标。本文将分别利用 FNN、RNN 与 CNN 模型介绍其基本方法、理论基础与典型神经网络结构。
依存分析¶
依存分析用于确定句子中词语之间的句法依赖关系。依存关系结构可作为下游任务的特征,增强模型对句法层级的理解能力。
语言规则说明¶
依存分析将句子构建为一棵有向树,树根对应主要谓词,其他词语依附于其支配词。在实际建模中不直接使用语言学规则,而是采用可操作的算法框架进行解析。
传统方法¶
最具代表性的算法是 Nivre (2003) 的 Greedy Deterministic Transition-based Parsing。该框架利用 Stack、Buffer 与依存集合 A 表示解析状态,通过 shift、left-arc、right-arc 三类动作逐步构建依存树:
- shift:将一个 token 从 Buffer 推入 Stack;
- left-arc:为 Stack 顶部两项建立左依赖关系,并记录到集合 A;
- right-arc:建立右依赖关系,与 left-arc 对称。
具体如下图所示:
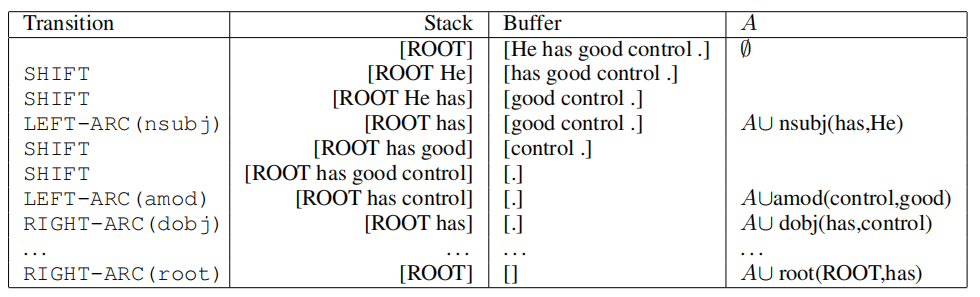
若语言含有 \(n\) 种依存关系,则模型需预测 \(2n+1\) 个类别,使得解析过程可被建模为标准多分类问题。
传统方法依赖大量人工特征,特征稀疏且维度扩张严重。现代方法的改进主要体现在特征自动学习机制上,显著提升泛化能力。
全连接神经网络¶
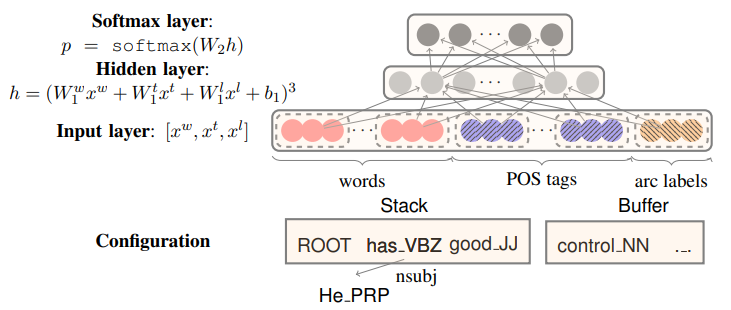
Chen & Manning (2014) 1 提出使用两层 FNN 网络直接预测转移动作。模型输入包括当前状态下的若干词向量、词性标签与依存标签,输出为转移动作类别。其关键在于利用词向量与网络结构自动学习紧凑特征,以减少人工设计成本,提高解析速度和精度。
模型结构如下图所示:
命名实体识别¶
命名实体识别属于序列标注任务。目标是为序列中每个 token 指定标签,如人名、地名、组织名等。序列标注任务还包括词性标注等,因此其建模方式具有普适性。
语言规则说明¶
序列标注采用 BIO 或 BIOES 等编码方案,将连续实体边界显式化,确保实体片段可被精确识别。模型需同时捕获局部上下文与长距离依赖,尤其在复杂句式下更为关键。
传统方法¶
传统方法包括隐马尔可夫模型 (HMM)、条件随机场 (CRF) 等。HMM 适合使用生成式建模标签序列,但难以利用丰富特征;CRF 通过判别式建模增强特征表达能力,但依赖人工特征工程。
循环神经网络¶
RNN 尤其是长短时记忆 (Long Short-term Memory, LSTM) 模型能够捕获序列的长依赖结构,在命名实体识别中表现良好。典型流程包括:
- 将 token 映射为词向量;
- 使用双向 LSTM 提取前后文信息;
- 采用全连接层或 CRF 解码层预测标签。
双向结构可同时利用左、右上下文,使模型在句法复杂区域保持稳定性能。LSTM 的门控机制可防止梯度消失,从而支持长序列建模。
情感分类¶
情感分类通常被视为句子或文档级的文本分类任务,目标是判断文本表达的情绪倾向,如正向、负向或中性。该任务主要关注语义与篇章结构,而非细粒度句法分析。
语言规则说明¶
情感表达可能跨越多个句子,或由隐含语义触发,因此模型需具备捕捉局部情绪线索与整体语义趋势的能力。传统词袋模型难以处理语序、否定词或长距离依赖。
传统方法¶
传统方法包括 TF‑IDF + 逻辑回归、SVM 等线性模型。这些方法在词序无关的假设下得到稀疏特征表示,但对否定结构、转折结构等情感变化不敏感。
卷积神经网络¶
CNN 通过局部卷积核抽取 n‑gram 层级的局部特征,可有效识别关键情感短语。典型流程如下:
- 将文本映射为词向量矩阵;
- 使用多尺寸卷积核提取不同尺度的局部特征;
- 通过最大池化获得全局特征表达;
- 使用全连接层输出分类结果。
图卷积神经网络 (GNN) 可在句法树或图结构上进一步建模文本,利用依存关系捕获更深的情感线索。例如将句法依存树作为图结构,节点为 token,边为依存弧,通过图卷积传播上下文信息,使模型在长距离依赖处理上具备优势。