TurboDiffusion
TurboDiffusion 是清华 MLSys 团队近日提出的视频生成加速方案。其基于 Wan2.1 T2V 和 Wan2.2 I2V 模型进行了百倍加速,且视频质量损失较小。本文尝试解读其加速方案,并推广到其他模型上。
基本概念¶
Wan2.1¶
Wan2.1 模型架构:
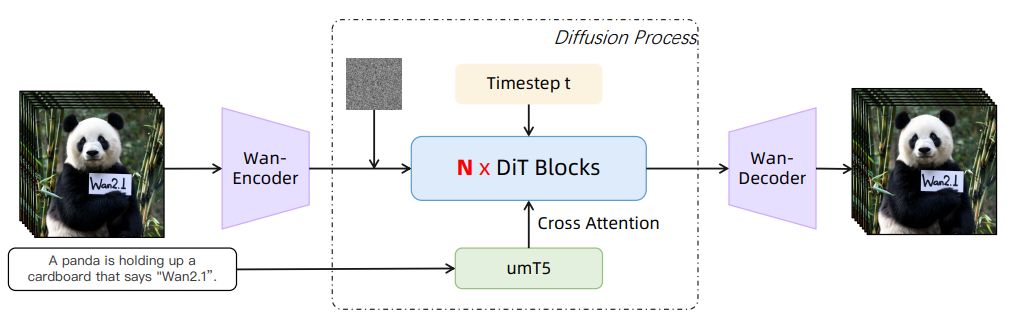
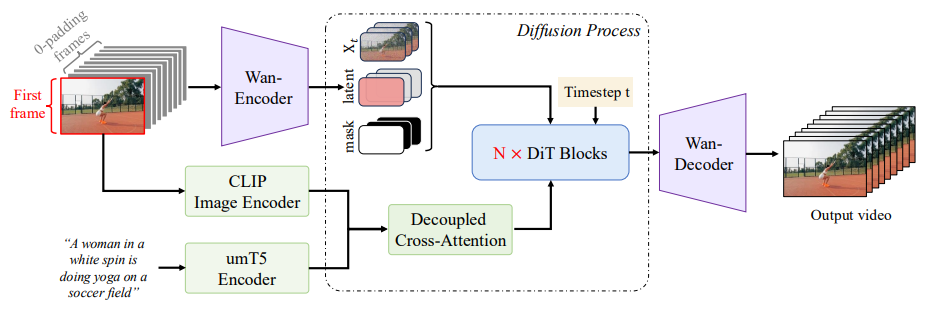
Wan2.1 I2V 模型架构:
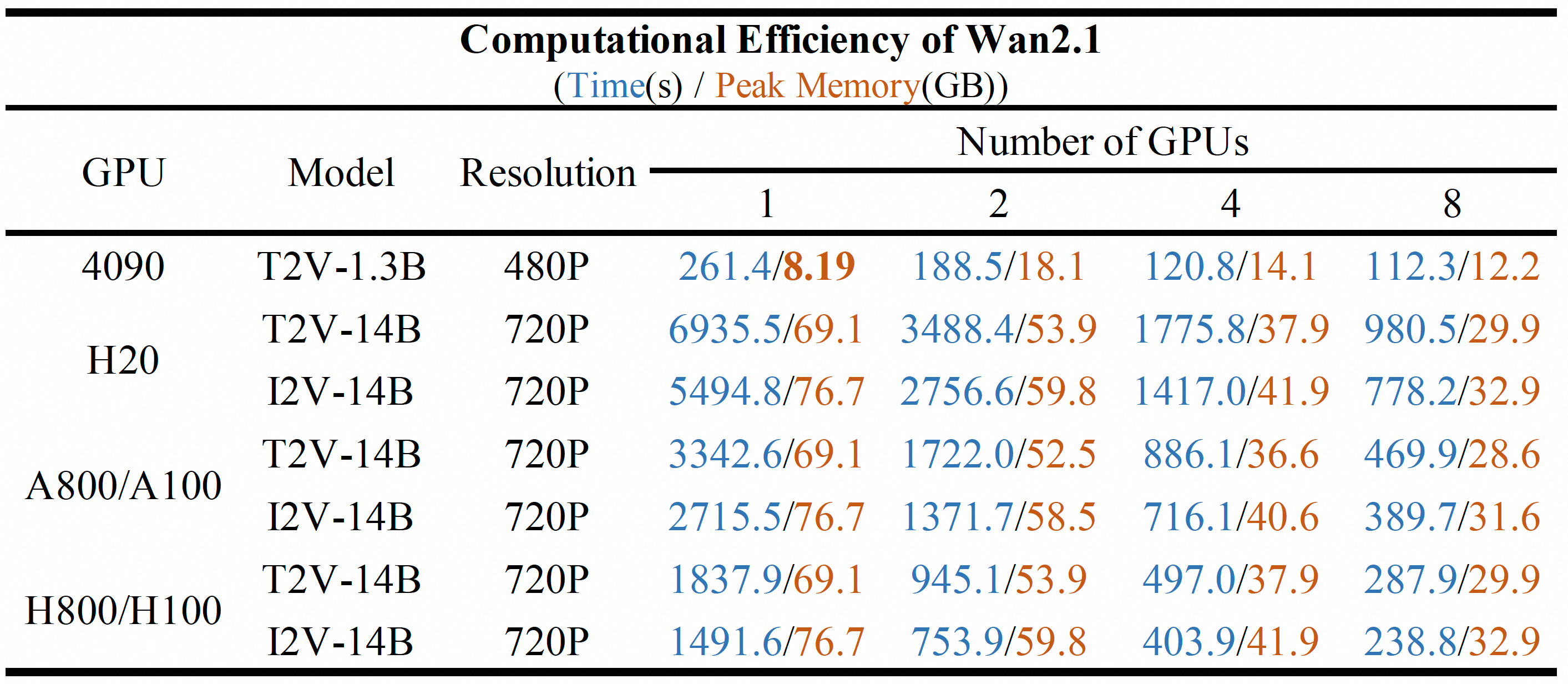
Wan2.1 计算效率:
Wan2.2¶
模型架构方面,相较于 Wan2.1,Wan2.2 主要引入了混合专家 (Mixture-of-Experts, MoE) 架构:

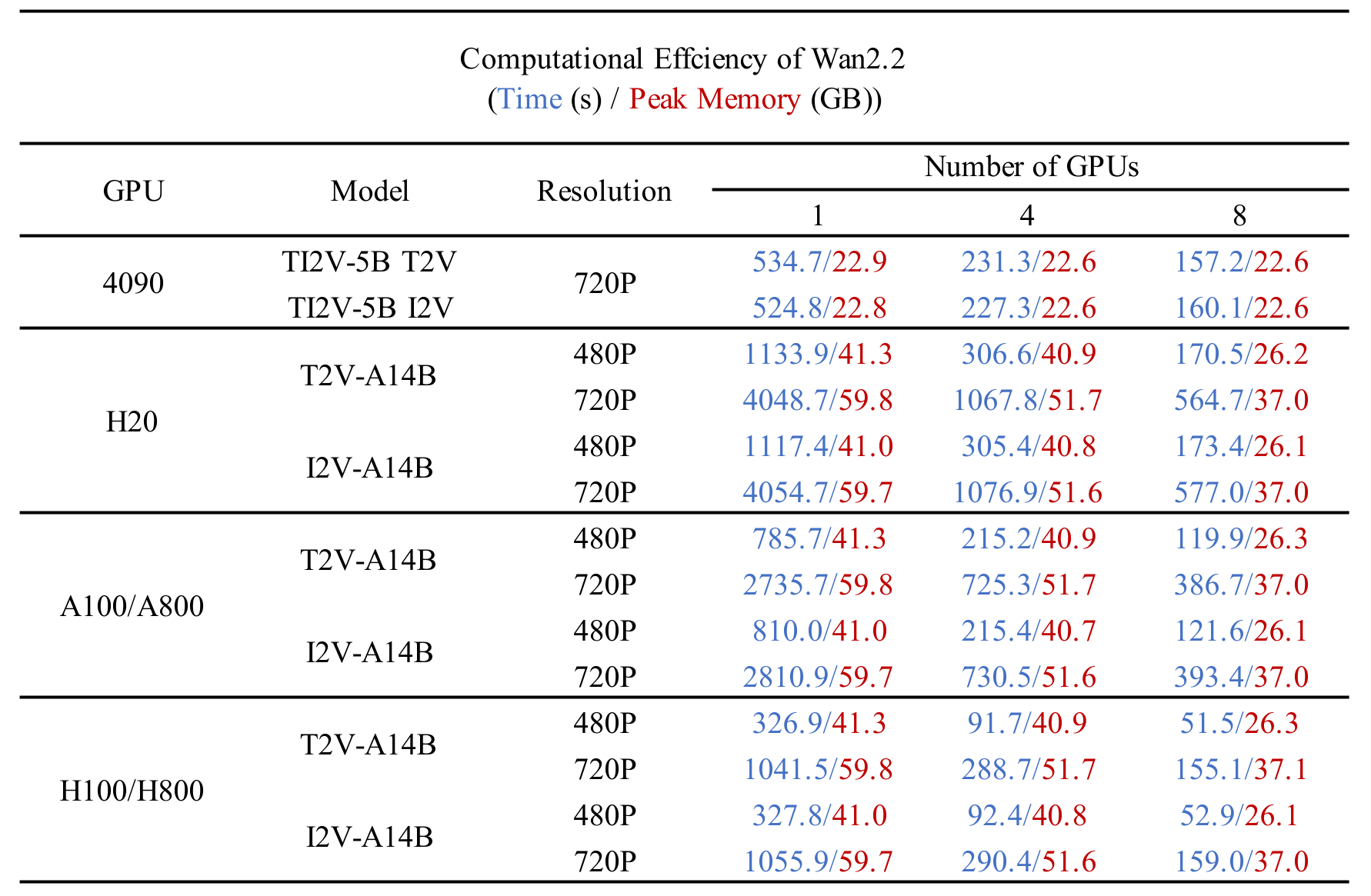
Wan2.2 计算效率:
注意力加速手段¶
目前主流的注意力优化机制主要从四个方面入手:
- 线性注意力,比如:LightningAttention 等
- 稀疏注意力,比如:SpargeAttention 等
- 从硬件层面优化,比如:FlashAttention、SageAttention、xFormers 等
当然,也可以混合上述注意力优化方案。比如:
- Sparse-Linear Attention 融合了线性注意力和稀疏注意力
- SpargeAttention 融合了线性注意力、稀疏注意力和 SageAttention
FlashAttention¶
FlashAttention 提供了注意力计算的 Python API 接口。也是 Wan2.1 和 Wan2.2 模型使用的注意力加速手段。
目前,FlashAttention2 可以使用 PyPI 安装,FlashAttention3 针对 Hopper 架构的 GPU 做了优化,需要基于源码编译安装。
使用 FlashAttention2 需要导入以下包:
| Python | |
|---|---|
使用 FlashAttention3 需要导入以下包:
| Python | |
|---|---|
两个版本的 接口 一致。
SageAttention¶
SageAttention 是清华大学 MLSys 团队提出的基于硬件的注意力加速手段,可以作为 FlashAttention 的平替,并且代码侵入性更低,可以 直接替换 PyTorch 的缩放点积函数:
| Diff | |
|---|---|
TurboDiffusion¶
TurboDiffusion 在以下模型上展开了实验:
- Wan2.1-T2V-1.3B (480P)
- Wan2.1-T2V-14B (480P, 720P)
- Wan2.2-I2V-A14B (720P)
其在单卡 RTX 5090 上获得了极快的推理速度:
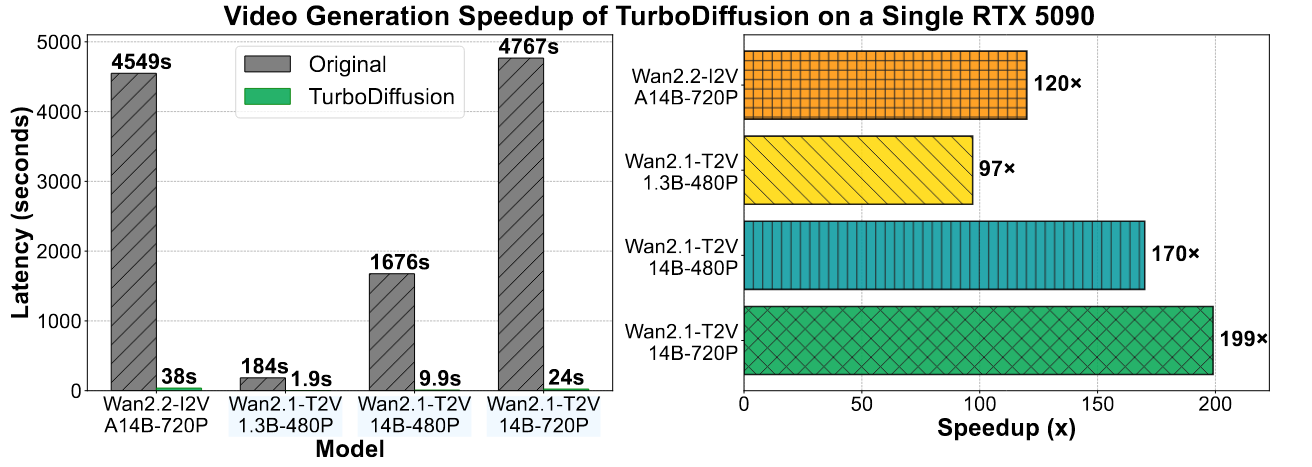
TurboDiffusion 在训练和推理阶段分别使用了不同的优化方案。
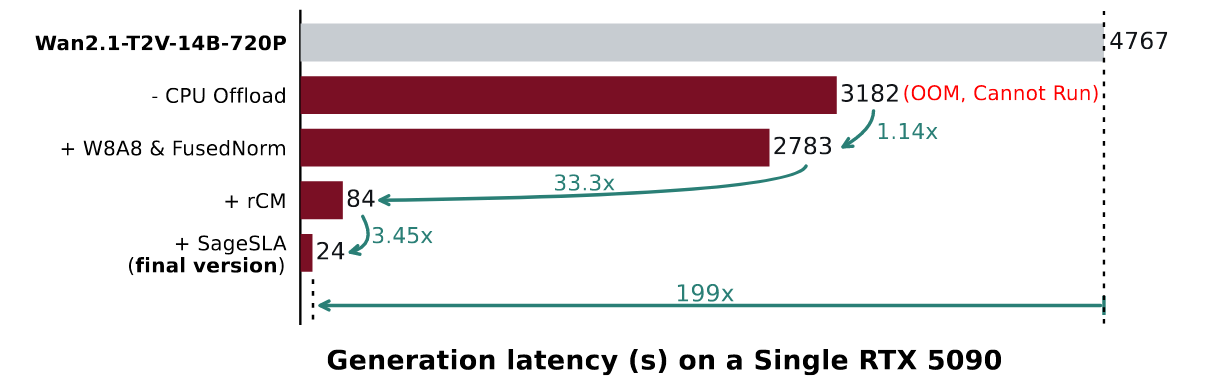
训练阶段:
- 使用 SLA 微调模型,更换 Attention 计算逻辑;
- 使用 rCM 蒸馏模型,减少 Diffusion 降噪步数;
- 上述两步同时进行分别得到一个新模型,合并后得到最终模型。
推理阶段:
- 使用 SageSLA 替代 SLA
- 减少降噪步数
- 量化线性层
消融对比如下:
ToDo List¶
- 复现 Wan2.1-T2V-1.3B 的 SLA 训练。
- 复现 Wan2.1-T2V-1.3B 的 rCM 训练。
- 应用在 Wan2.2-T2V-5B 模型上。