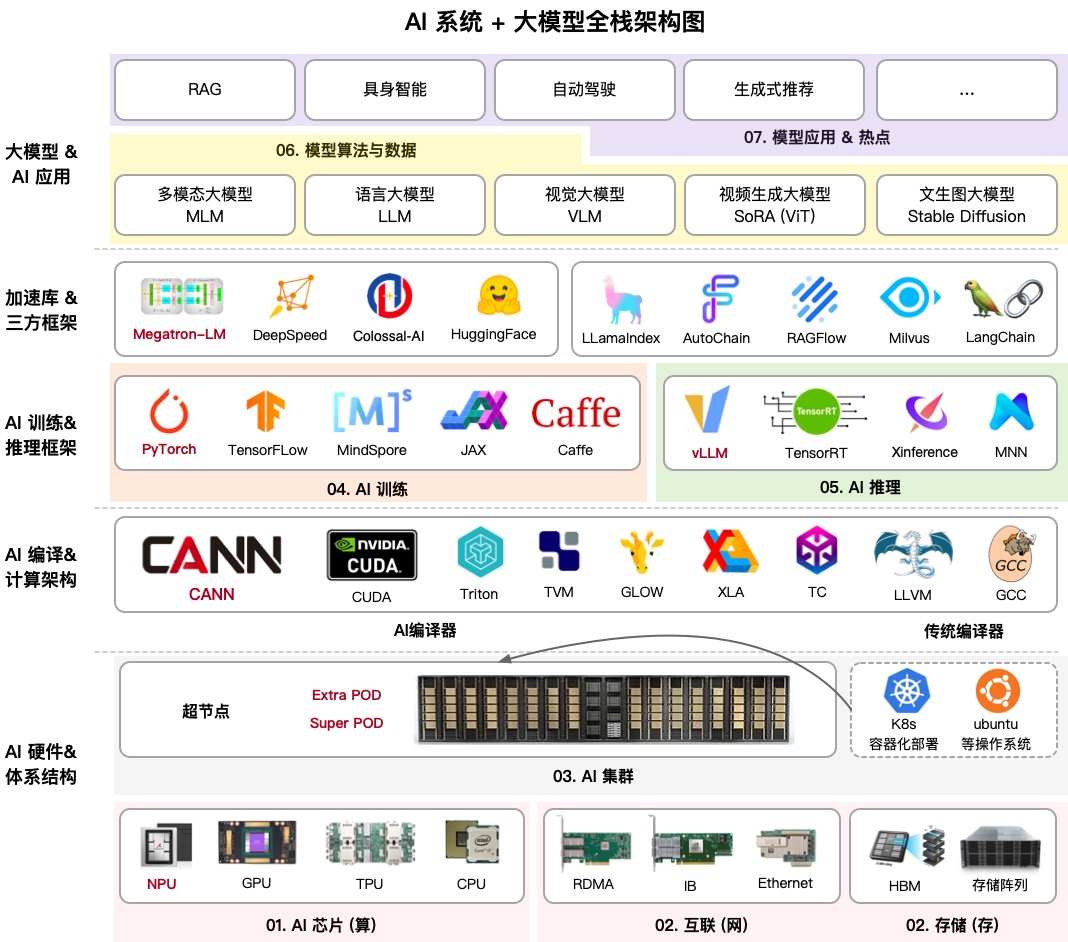
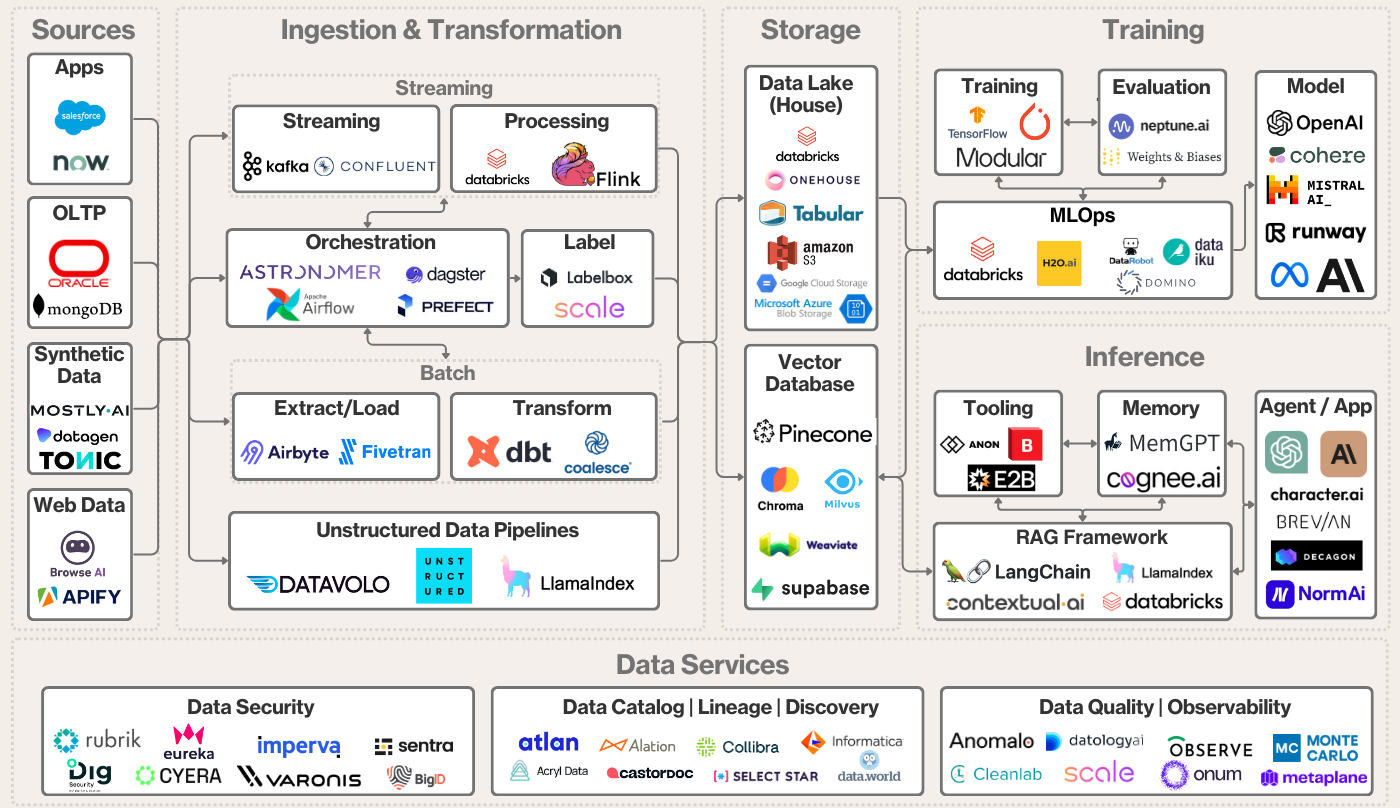
基础设施
AI 基础设施 (AI Infrastructure, AI Infra) 决定了我们能否在「稳定、高效、低成本」的前提下完成模型的「训练与部署」。
自底向上可以将 AI Infra 划分为以下四个部分:
- 硬件,提供并行算法和高效通信。包括:显卡 (GPU, TPU, NPU, Ascend)、网络通信 (InfiniBand, NVLink, RoCE)、存储 (NVMe SSD) 等;
- 数据,提供训练语料和数据管理服务。包括:数据采集与处理、数据管理与分发 (Hugging Face, ModelScope)、向量数据库等;
- 训练框架,将硬件资源转化为模型能力。包括:深度学习框架 (PyTorch, TensorFlow)、编译与优化(TorchInductor、Triton、XLA、TVM)、训练效率提升(混合精度训练)等;
- 推理框架,将模型部署为可用的服务,实现低延迟、高吞吐、低成本的在线推理。包括:模型压缩(量化、蒸馏、剪枝)、高效推理机制(KV Cache、Paged Attention、动态批处理)、算子与内核优化(CUDA Graph、Flash Attention、TensorRT)、模型编排与路由(多模型选择、负载均衡)、安全与治理(提示词防注入、内容过滤、访问控制)、部署框架(vLLM、SGLang)等。
部分参考: