基本概念
本文记录 Python 的基本概念。
安装 Python¶
安装 Python 的方法有很多,主要有以下几种:
- 【新人小白推荐】基于 python 安装包 管理 Python;
- 【数据科学推荐】基于 conda 管理 Python;
- 【现代工程推荐】基于 uv 管理 Python。
后两种方法详见 项目管理。
解释器¶
Python 是一门解释型语言,代码不会被提前编译成机器码,而是由解释器在运行时逐行转换并执行。解释器会先将 .py 代码转换为 .pyc 字节码,然后逐行执行字节码得到运行结果。根据场景的不同,执行字节码的实现也不同,目前主流的有以下几种实现:
| 实现 | 开发语言 | 字节码执行方式 | 特点 | 典型应用场景 |
|---|---|---|---|---|
| CPython | C | 逐条解释 | 官方标准实现,生态最全,速度中等 | 默认实现、科研计算、Web 后端等 |
| PyPy | Python | 逐条解释,但会在运行时将热点字节码即时 (Just In Time, JIT) 编译为机器码,直接在 CPU 上执行 | 执行速度快,适合长时间运行的计算任务;但兼容性稍差 | 高性能计算、高并发等 |
| Jython | Java | 将 Python 源码直接编译成 Java 字节码,然后由 JVM(Java 虚拟机)执行 | 能与 Java 无缝集成;但性能依赖 JVM 优化,启动速度稍慢 | 需要在 Java 环境中使用 Python 脚本 |
包¶
Python 以包 (Package) 的形式组织不同的功能模块,每一个 .py 文件就是一个模块,模块中含有对应的类和函数。可以简单地将 Python 中的包与 C++ 中的命名空间 类比——同一个包中不可出现同名模块,不同的包中可以出现同名模块。
Python Package 的基本结构如下图所示:
graph TB
p(包)
sp(子库)
m1(模块1)
m2(模块2)
m3(模块3)
c1(类1)
c2(类2)
f1(函数1)
p --> m1 & m2 & sp
sp --> m3
m2 --> c1 & c2 & f1得益于 Python 便捷的开发逻辑,其第三方包相当丰富。包分发系统 (Python Package Index, PyPI) 可以非常便捷地分发和管理第三方包。
虚拟环境¶
不同的项目往往依赖不同的包,为了避免出现包的版本冲突,一般推荐按照项目进行包的隔离,隔离出来的环境被称作虚拟环境。所谓虚拟环境,本质上就是拷贝(或链接)一个 Python 解释器,然后将各种包安装在指定目录下,从而起到了隔离的效果。
*注:虚拟环境并不代表根解释器的完全拷贝,有些项目无关的文件并不会拷贝,所以不能删除根解释器。
各种 IDE 都提供了可视化的虚拟环境创建方法,但为了彻底理解虚拟环境的工作原理,这里仅讨论最朴素的创建方法——使用 Python 标准库中的 venv 模块自定义虚拟环境。
创建环境:
激活环境:
退出环境:
项目管理¶
一般来说,对于一个规范的 Python 工程,都需要确保能够被复现,此时就需要用上 Python 项目管理工具了。目前主流的主要有以下几个:
pip。Python 自带的包管理工具。特点:轻量、传统、兼容性好,但速度较慢;conda。Anaconda 和 Miniconda 的包与环境管理工具,其中 Miniconda 是 Anaconda 的精简版,推荐使用 Miniconda。与pip不同的是,conda不仅可以以虚拟环境的形式管理 Python 包,还能很方便地管理 Python 版本。这对于很多对 Python 版本有要求的项目来说很方便。特点:强大、跨语言、数据科学常用,但相对臃肿;uv。一个超高速的 Python 包与环境管理工具。它的设计目标是成为pip+venv+virtualenv+pip-tools+pipx的统一替代品,同时兼具 Rust 语言的高性能和 Python 工具的灵活性。特点:新一代工具,统一包管理与环境管理,速度极快,未来有望成为主流。
工具安装¶
安装 Python 时自带,无需额外安装。如果没有,可以手动安装:
以在 Linux 系统安装 Miniconda 为例,其他系统上的安装方法见 Anaconda 官网):
管理 Python¶
无法管理 Python 版本,只能依赖已有的 Python。
可以在创建虚拟环境的时候指定 Python 版本,详见 管理虚拟环境。
管理包¶
管理虚拟环境¶
无法管理,但是可以借助 Python 自带的 venv 库,如 虚拟环境 中介绍的。
同步环境¶
管理配置¶
uv 没有 config 子命令一说,各种配置都被拆解为对应的子命令了,强烈建议使用 uv --help 查看各种命令的用法。关于配置的查询顺序和优先级,详见 uv | Configuration files 官方文档。
配置下载源¶
管理缓存¶
其他常用操作¶
PEP¶
Python 增强提案 (Python Enhancement Proposal, PEP) 是 Python 社区用来规范 Python 语言的。下面罗列一些比较常用的规则。
PEP 503: Simple Repository API¶
2015 年 Python 社区提出了 包名标准化 制度:
- 所有单个或连续的
- . _字符都会被替换为单个-字符; - 所有字母都会被转化为小写字母。
例如 FLASH-atTn、flash_attn、flash___attn 等都会被解释为 flash-attn。
导入机制¶
在 Python 中,模块化开发的核心思想是将代码拆分为多个模块 module 和包 package,通过导入机制复用和组织代码,因此了解导入机制非常重要。
以下面的项目结构为例:
模块的搜索顺序¶
当用 import xxx 尝试导入某一个模块时,Python 会按以下顺序搜索模块:
- 当前执行脚本所在目录。例如执行
python main.py时,解释器会先在my_project中找; - 环境变量
PYTHONPATH指定的路径。可以通过export PYTHONPATH=/path/to/mylibs指定; - 标准包路径。Python 自带的包,如
os、sys等; - 第三方包路径。通过
pip install安装的库都在这里,即site-packages目录。
可以打印 sys.path 列表查看解释器的模块搜索路径:
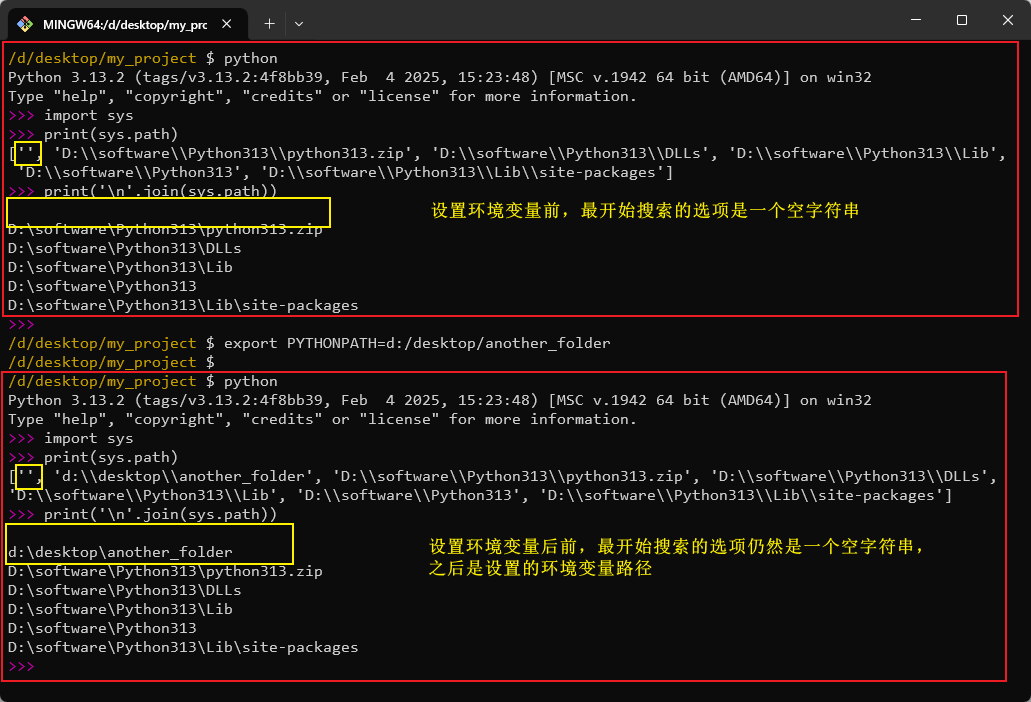
可以看到解释器的确按照上述顺序搜索模块。其中空字符串就表示项目所在根目录,对于示例项目,就是 /path/to/my_project。
注意:PYTHONPATH \(\ne\) 虚拟环境激活。
- 设置
PYTHONPATH只是告诉解释器额外去某个目录找模块,并没有改变 Python 的运行环境。 - 虚拟环境在激活时,会做的不仅仅是修改
PYTHONPATH,它还会:- 改变
sys.prefix和sys.executable,让解释器以虚拟环境为主; - 注入
sitecustomize.py和site.py的钩子,使包索引、依赖解析与虚拟环境匹配; - 修改动态链接库的搜索路径。
- 改变
模块的导入方式¶
分绝对导入和相对导入两种。
绝对导入。从项目根目录开始写路径,可以保证路径清晰,适合跨包引用。例如:
相对导入。基于当前模块所在位置,使用 . 或 .. 来表示相对路径,便于包的内部维护。例如:
关于 __name__¶
在 Python 的导入与运行机制中,__name__ 变量起着关键作用,它决定了当前模块在解释器眼中的身份。而决定 __name__ 变量取值的,在于模块的运行方式。
直接运行模块。例如,使用 python path/to/my_project/pkg/math_utils.py 运行模块 math_utils.py 时:
-
模块身份。此时
math_utils.py的__name__ = '__main__',解释器认为它是“顶层脚本”,而不是pkg包中的子模块; -
搜索路径。Python 会将当前文件所在目录作为根目录,即
sys.path[0] = path/to/my_project/pkg。在解释器眼中,pkg不是一个包,而只是一个普通目录; -
运行结果:
-
如果使用「绝对导入」,只能导入
pkg目录下的模块;若试图导入外层模块,会报错: -
如果使用「相对导入」,会报错:
因为 Python 此时并不知道
math_utils.py有“父包”,它被当成独立文件执行。
-
通过 -m 参数运行模块。例如,使用 python -m pkg.math_utils 运行模块 math_utils.py 时:
- 模块身份。此时
math_utils.py的__name__ = '__main__',但仍属于pkg包的子模块; - 搜索路径。Python 会将执行命令的当前目录作为根目录,即
sys.path[0] = path/to/my_project。解释器能正确识别pkg是顶层包; - 运行结果。绝对导入、相对导入都能正常工作。
if __name__ == '__main__' 的应用场景。在实际开发中,包内子模块往往既要被其他模块导入,又希望能够单独测试。此时我们通常会在模块末尾写:
这样当模块被 import 时,测试代码不会执行;当使用 python -m pkg.math_utils 运行时,测试代码才会执行,从而实现子模块的“就地单测”。
总结一下。直接运行文件时,解释器眼里它是孤立的脚本;用 -m 运行时,它才是包的一部分:
- 导入规则:顶层模块「必须」使用绝对导入;包内模块之间「最好」使用相对导入;
- 运行规则:顶层脚本「可以」直接
python xxx.py运行;使用相对导入的包内子模块「必须」增加-m参数运行。
变量与作用域¶
理解作用域是理解一门编程语言的开始,这里就以变量为载体,结合与 C++ 的对比进行讲解。
变量引用¶
在 C++ 和 Python 中,赋值语句的语义是完全不同的。类比:C++ 变量像「盒子」,赋值就是再拿一个盒子装一份拷贝;而 Python 变量像「标签」,赋值就是多贴几个标签在同一个盒子上。下图生动的展示了 Python 变量的意义:

C++:赋值会产生拷贝(盒子模型)。给变量赋值时,会重新申请内存空间,把数据复制过去。
例如下面的程序。输出的内存地址不同,说明 a 和 b 是两份独立的数据。:
Python:赋值仅仅是增加引用(标签模型)。所有变量其实都是「标签」,指向同一块数据。
例如下面的程序。三个变量的内存地址完全一样,说明它们指向同一份数据:
可变与不可变类型¶
理解引用后,关键在于弄清修改变量时会发生什么,而这与 Python 的数据类型息息相关。Python 的数据类型分「可变」和「不可变」两类。
可变类型(列表 list、字典 dict、集合 set)。修改操作为原地修改,不会新开内存,因此所有引用同时生效。
例如下面的程序。修改了其中一个变量的值以后,三个可变数据类型变量 \(a,b,c\) 指向的内存空间没有发生改变,同时其余所有变量也都跟着改变:
不可变类型(整数 int、浮点数 float、字符串 str、元组 tuple)。修改操作本质是「重新赋值」,会开辟新内存,原来的数据保持不变。
例如下面的程序。另一个引用变量 \(t\) 在进行拼接操作后,对应的内存地址发生了改变,也就是说申请了新的内存空间:
变量拷贝¶
因为 Python 的赋值只是引用,所以如果要真正「复制」,需要用 copy 模块。该模块有以下两种拷贝模式:
- 浅拷贝
copy.copy():只复制第一层,嵌套的可变元素依然是引用; - 深拷贝
copy.deepcopy():递归复制,得到一份全新的数据。
例如下面的程序。:
变量作用域¶
Python 查找变量的顺序遵循 LEGB 规则:
- Local:先查找当前函数内的变量;
- Enclosing:再查找外层函数的变量;
- Global:然后查找全局变量;
- Built-in:最后查找内置变量和其他导入的包中的变量。
当且仅当需要修改外层变量时,才需要显示声明变量的未知。一共有两种:
global var1, var2, ...:显式声明全局变量;nonlocal var1, var2, ...:显式声明往外一层函数的变量。
例如下面的程序:
Python 的 class 变量也完全遵守上述规则,只不过增加了两种变量:实例变量和类变量(私有变量和保护变量的作用域涉及到面向对象,和本节讨论的内容无关,不予讨论)。具体地:
- 实例变量:通过
self.var定义,每个实例独立; - 类变量:直接定义在类中,所有实例共享。
例如下面的程序。不同的类中,类变量的地址是相同的,实例变量的地址不同: