网络层
网络层主要有三类协议:IP 协议、路由选择协议和 ICMP 协议。假设主机 A 需要向另一个网络下的主机 B 进行交互,那么主机 A 首先需要将数据依次进行链路封装、IP 封装,然后根据路由器中通过路由选择算法存储的路由转发到下一跳路由器,不断转发直到到达主机 B,期间如果发生超时、不可达等问题,就会通过 ICMP 协议回发错误信息。
基本概念¶
网络层使用数据链路层的服务,实现路由选择、拥塞控制与网络互联等基本功能,向传输层的端到端传输连接提供服务。
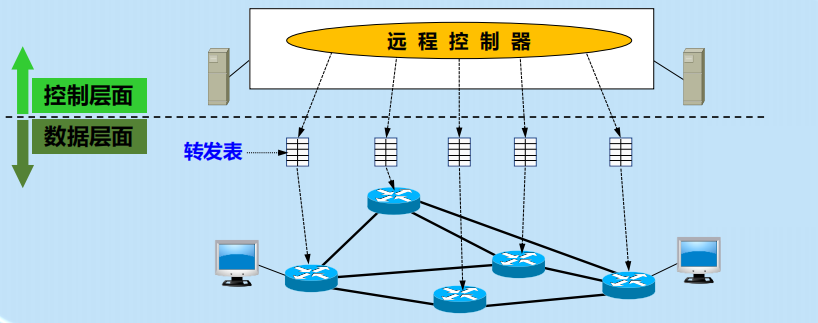
基本框架如上图所示,其中:
- 远程控制器根据路由选择算法计算出最佳的路由,在每一个路由器中生成其正确的转发表;
- 路由器负责查找转发表然后转发分组。
网络层可以提供面向连接的可靠传输,即通过“虚电路”技术;也可以仅提供不面向连接的尽力而为传输服务,把可靠传输的任务交给端系统(比如传输层、应用层)。
IPv4 协议¶
IP 协议是一种无连接、不可靠的分组传输协议,提供尽力而为 (best effort) 的服务。IP 协议屏蔽了互联的网络在数据链路层、物理层协议与实现技术上的差异,实现了网络互联。

IPv4 字段分析¶
下图展示了 IPv4 的首部字段,最少由 20 个字节组成:
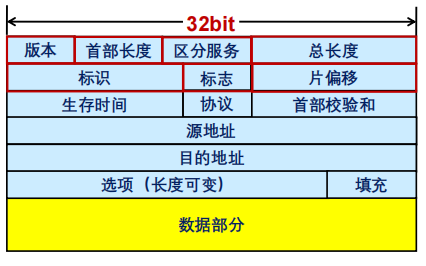
各字段解释如下:
-
版本: 4 bit,表示采用的 IP 协议版本;
-
首部长度: 4 bit,表示整个 IP 数据报首部的长度;
-
区分服务: 8 bit ,该字段一般情况下不使用;
-
总长度: 16 bit ,表示整个 IP 报文的长度, 能表示的最大字节为 \(2^{16}-1 = 65535\) 字节;
-
标识: 16 bit , IP 软件通过计数器自动产生,每产生 1 个数据报计数器加 1;在 IP 分片以后,用来标识同一片分片;
-
标志: 3 bit,目前只有两位有意义。MF 置 1 表示后面还有分片,置 0 表示这是数据报片的最后 1 个。DF 置 1 表示禁止分片,置 0 表示允许分片;
-
片偏移: 13 bit,表示 IP 分片后,相应的 IP 片在总的 IP 片的相对位置;
-
生存时间 (Time To Live, TTL):8 bit,表示数据报在网络中的生命周期,用“通过路由器的数量”来计量,即跳数(每经过一个路由器会减 1);
-
协议:8 bit,指出应将数据部分交给哪一个上层协议(例如 TCP、UDP、ICMP 等)处理;
-
首部校验和:16 bit ,仅对数据报首部进行校验,不对数据部分进行校验,这是因为 IP 协议仅提供尽力而为的分组传输服务,这样可 以减少路由器对每个分组的处理时间,从而提高分组转发的效率;
计算示例

-
源地址:32 bit,标识 IP 片的发送源 IP 地址;
-
目的地址:32 bit,标识 IP 片的接收源 IP 地址;
-
选项:可扩充部分,具有可变长度,定义了安全性、严格源路由、松散源路由、记录路由、时间戳等选项;
-
填充:用全 0 的填充字段补齐为 4 字节的整数倍。
IPv4 数据报分片¶
当数据报大小超过数据链路的 MTU 时,端系统、路由器可以基于 IPv4 协议将数据报进行分片,最终在目的 IP 对应的目的端系统进行重组。
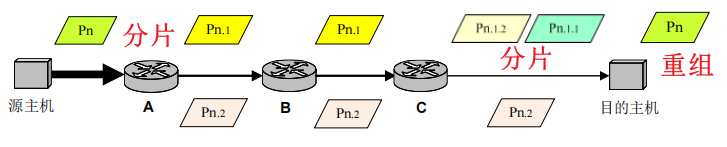
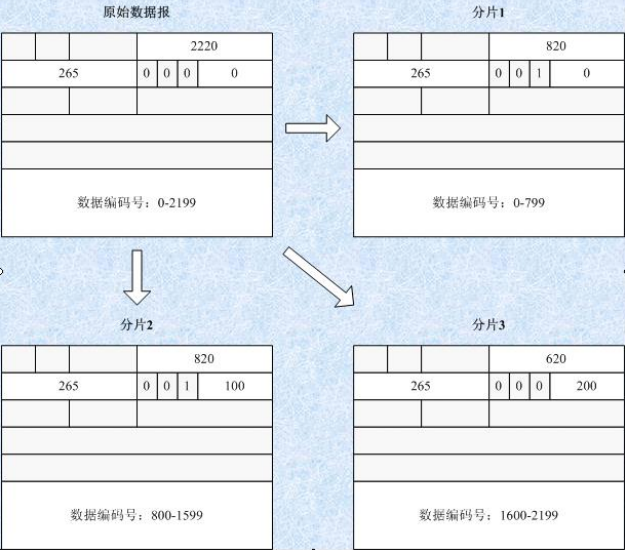
IPv4 数据报分片涉及到「标识、标志和片偏移」三个字段,如下图所示:
IPv4 的 CIDR 技术¶
互联网需要一个全局的地址系统,给每一台主机或路由器的网络连接分配一个全局唯一地址。网络中的每一个主机或路由器至少有一个不重复的 IP 地址。一个 IPv4 地址从左到右由「网络号和主机号」两部分组成,如下图所示:
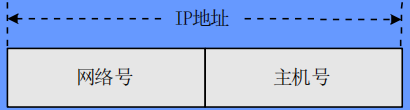
这种划分策略被称为无类别域间路由选择 (Classless Inter-Domain Routing, CIDR)。其中网络号与主机号的划分通过再维护一个 32 位的子网掩码来实现,例如 255.255.0.0 表示 IPv4 地址中前 16 位为网络号,后 16 位位主机号。一些特殊的网络地址如下:
-
网络地址(网关):主机号全为 0;
-
主机地址:网络号全为 0;
-
直接广播地址:主机号全为 1,只能作为分组中的目的地址,用来将一个分组以广播方式发送给特定网络上的所有主机;
示意图
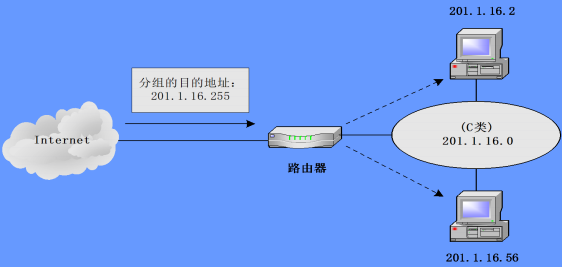
-
受限广播地址:全 1 地址,即
255.255.255.255,用来将一个分组以广播方式发送给本网的所有主机,分组被本网的所有主机接受,路由器则阻挡该分组通过;示意图
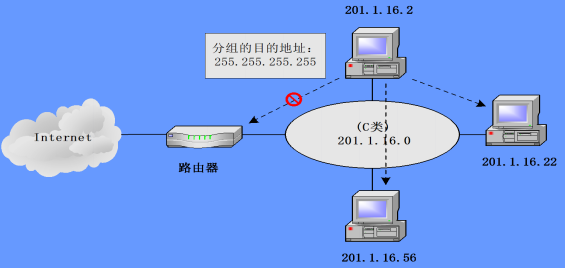
-
回送地址:网络号为 127,例如
127.x.x.x; -
本机地址:全 0 地址,即
0.0.0.0。
IPv4 的 NAT 技术¶
由于 IPv4 地址的短缺以及互联网迁移到 IPv6 的进程缓慢,因此需要一种能够在短时期内快速缓解地址短缺的问题得方法,网络地址转换 (Network Address Translation, NAT) 技术被提了出来。其核心思想就是让一个局域网中的每一个设备动态申请 IP,等到使用结束后主动释放掉这个 IP 以供后来的设备使用联网服务。
IPv4 的数据转发与 ARP 协议¶
这里介绍网络层与数据链路层的过渡逻辑。我们知道,同一个局域网内的终端通信仅仅需要设备的 MAC 地址,这就需要每一台设备都缓存号 IPv4 与 MAC 的映射。当 A 设备知道 B 设备的 IP 但是不知道其 MAC 地址时,就会通过局域网内广播地址解析协议 (Address Resolution Protocol, ARP) 请求来获得 B 设备的 ARP 响应,进而通过 MAC 地址进行链路连接。推而广之,不同局域网下的通信也就和 ARP 协议息息相关了。
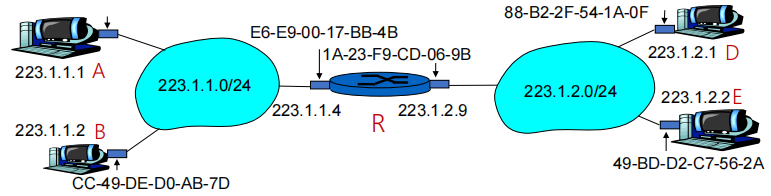
如上图所示,假设 A 设备需要发送一些数据给 E 设备,那么就有以下流程(对用户来说是透明的):
- A 发送 ARP 广播收到 R 路由器的 ARP 响应,从而得知 R 的 MAC 地址;
- A 封装 MAC 帧将数据报发送给 R;
- R 在其另一个局域网段内通过 ARP 协议获取 E 的 MAC 地址(如果 R 的
223.1.2.9网段缓存了 E 的 MAC 地址那就可以直接查出来); - R 将 A 的数据报重新封装 MAC 帧然后转发给 E。
IPv4 的 IP 匹配策略¶
数据在路由表、主机上转发时,需要根据缓存其中的路由表进行,即需要查询从目的 IP 到下一跳 IP 的转发端口,这涉及到了 IP 的匹配问题,为了确保匹配的正确性,需要将前缀匹配最长的 IP 作为匹配结果(这似乎很显然),可以使用 Trie 数据结构进行匹配优化。
IPv6 协议¶
为了应对 IPv4 的 32 位地址空间耗尽问题(CIDR 和 NAT 都无法从根本上解决地址短缺问题),及其分组头复杂难以实现扩充、缺少安全与保密方法等问题,IPv6 被设计了出来。
IPv6 字段分析¶
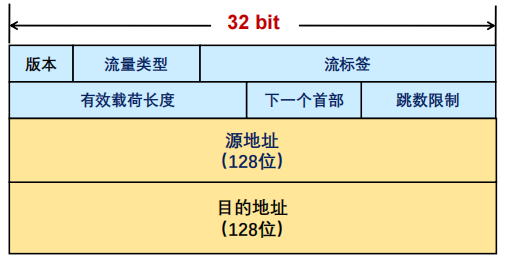
如上图所示,IPv6 有如下几个首部字段:
- 版本:4 bit,协议版本号,值为 6;
- 流量类型:8 bit,区分数据包的服务类别或优先级;
- 流标签:20 bit,标识同一个数据流;
- 有效载荷长度:16 bit,IPv6 报头之后载荷的字节数(含扩展头),最大值 64K;
- 下一个首部:8 bit,IPv6 报头后的协议类型,可能是 TCP/UDP/ICMP 等,也可能是扩展头;
- 跳数限制:8 bit,类似 IPv4 的 TTL,每次转发跳数减 1,值为 0 时包将会被丢弃;
- 源地址: 128 bit,标识该报文的源地址;
- 目的地址: 128 bit,标识该报文的目的地址。
IPv6 基本报头长度固定 40 字节,所有“选项”字段都在 IPv6 扩展头部分。与 IPv4 头部相比,有以下几点变化及其原因:
- 去除了“首部长度”字段。因为已经固定为了 40 字节;
- 去除“首部校验和”字段。直接不检验,提升转发速度。因为传输层和数据链路层的校验已经可以做到完美校验了,此处的校验属于是冗余;
- 将“标识”“标志”“片偏移”分片字段移至扩展头。因为 IPv6 设计为可以通过 Path MTU 机制提前知道路径上的 MTU,从而只在源端进行分片即可。
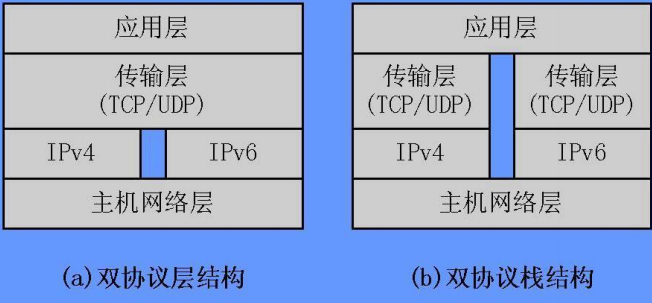
从 IPv4 过渡到 IPv6 的方法¶
要么让终端、路由器支持双协议,要么在经过异构网络时进行重新封装/解包。
双协议示意图:
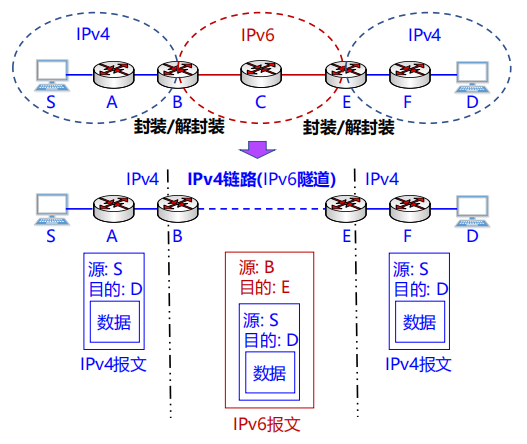
异构网络示意图:
路由选择¶
路由选择(简称路由)是指通信子网中的路由器根据通信子网的当前状况,按照一定的策略(传输时间最短、传输路径最短等),选择一条最佳的传输路径将分组发往目的主机,其核心就是路由选择算法。说白了就是怎么给路由器或主机配置路由表。
路由表示例
不怎么需要变化的小型网络可以自己动手配置一下路由表,但是规模一旦变大肯定就不合适了,需要基于动态路由选择算法自适应地配置每一台路由器的路由表。
同时,随着网络规模的增大,不可能把全世界的路由信息都存储到每一个路由器的路由表中,人们又设计了分层路由策略。每个地区的路由器归属到各自的自治系统 (Autonomous System, AS),自治系统内部使用内部网关路由协议 (Interior Gateway Protocols, IGP),每个自治系统域内的路由算法可以不同,例如:OSPF、RIP、IS-IS、IGRP、EIGRP 等;自治系统之间之间使用外部网关路由协议 (Exterior Gateway Protocols, EGP),各自治系统域之间的路由需统一,例如:BGP 协议。
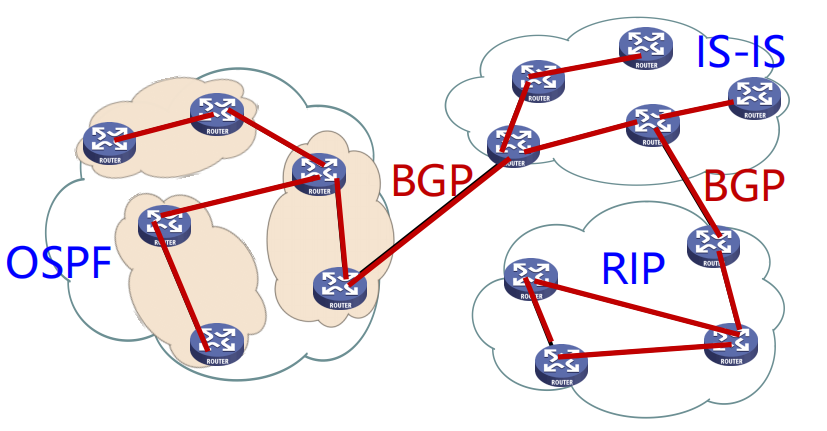
RIP 协议¶
即路由选择协议 (Routing Information Protocol, RIP)。该路由选择协议的路由选择算法是基于 Bellman-Ford 进行的。RIP 协议算法简单、易于实现,但是需要交换的信息量大导致收敛较慢。
OSPF 协议¶
即开放最短路径优先协议 (Open Shortest Path First, OSPF)。该路由选择协议的路由选择算法是基于 Dijkstra 进行的。使用 OSPF 协议的路由器可以通过相互发送消息得知整个区域的路由器状态,从而计算出最佳路由表。
BGP 协议¶
即边界网关协议 (Border Gateway Protocol, BGP)。负责不同 AS 之间的通信。
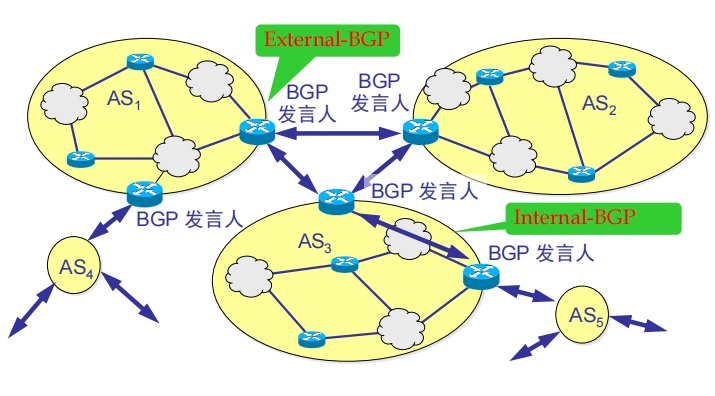
如上图所示,每个自治系统的管理员要选择至少一个路由器(通常是 BGP 边界路由器)作为该自治系统的“BGP 发言人”。每个 BGP 发言人不仅必须运行 BGP 协议外,还必须运行其所在自治系统所使用的内部网关协议(如 RIP 或 OSPF)。一个 BGP 发言人与其他自治系统中的 BGP 发言人要交换路由信息,如增加的路由、撤销过时的路由等,从而根据所采用的策略从收到的路由信息中找出到达其它 AS 的最佳路由。
ICMP 协议¶
IP 协议是一种无连接、不可靠的分组传送服务的协议,提供的是一种尽力而为的服务。为了提高 IP 分组交付成功的概率,网络层使用了互联网控制报文协议 (Internet Control Message Protocol, ICMP ),ICMP 协议允许主机或路由器报告差错情况和提供有关异常情况的报告。
ICMP 协议的特点:
- ICMP 差错报告采用路由器-源主机的模式,路由器在发现数据报传输出现错误时只向源主机报告差错原因;
- ICMP 不能纠正差错,它只是报告差错。差错处理需要由高层协议去完成。
ping 程序就是使用了 ICMP 协议的请求报文 - 响应报文来实现「测试目的站是否可达及了解其有关状态」的功能的。
其他¶
IGMP 协议¶
为了实现单一数据源向多个请求源发送数据的功能(多播功能),互联网组管理协议 (Internet Group Management Protocol, IGMP) 被设计了出来。
多播的场景有很多,例如:直播、联机游戏等。IGMP 协议使用 IP 分组传递 IGMP 报文,帮助路由器识别加入到一个组播组的成员主机。具体地:
- 主机加入新的多播组时需要向多播组的多播地址发送一个 IGMP 报文。本地的多播路由器收到 IGMP 报文后,记录该主机的 IP 地址,同时将组成员关系转发给互联网上的其它多播路由器;
- 组成员关系是动态的,本地组播路由器要周期性地使用 IGMP 报文探询本地局域网上的主机,以便知道这些主机是否还继续是组的成员。当一个主机不进行应答,超过一定时间之后 ,路由器将其地址从多播地址表中删除,该主机自动离开该组。
VPN¶
TODO
移动 IP 协议¶
TODO