语音信号处理
本文记录语音信号处理的入门学习笔记。部分参考内容如下:
- 理论:《现代语音信号处理(Python 版)》1、配套代码、全书目录
- 实践:Audio Course | Huggingface - (huggingface.co)。
成绩组成:出勤+测验(*2)+期末大项目。
数据预处理¶
更多内容参考:语音信号处理 | 凌逆战 - (www.cnblogs.com)
原始的模拟信号首先被麦克风捕捉,并由声音信号转化为电信号。接下来,电信号会由模数转换器 (Analog-to-Digital Converter, ADC) 经由采样过程转换为数字化表示。人类可感知的声音频率范围:20 Hz - 20 kHz,声音强度范围:0 dB - 130 dB。
语音信号大约有三种表示方法:时域表示(时谱图)、频域表示(频谱图)、时频域表示(语谱图)。其余的表示方法都是在前三者的基础之上进行一定的变换得来,但本质不变。具体地:
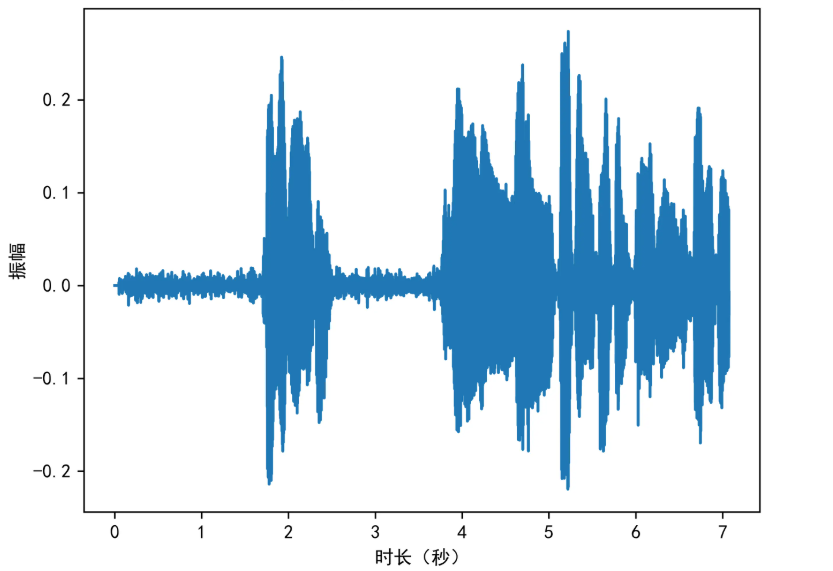 |
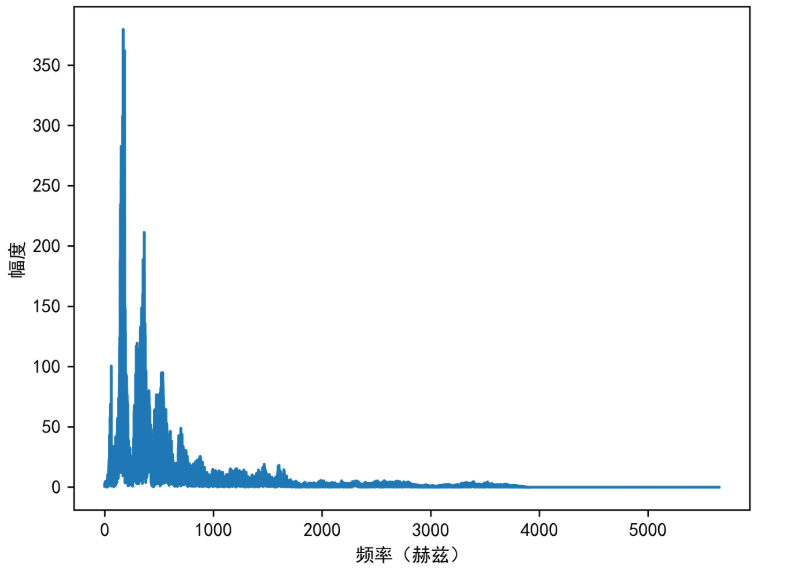 |
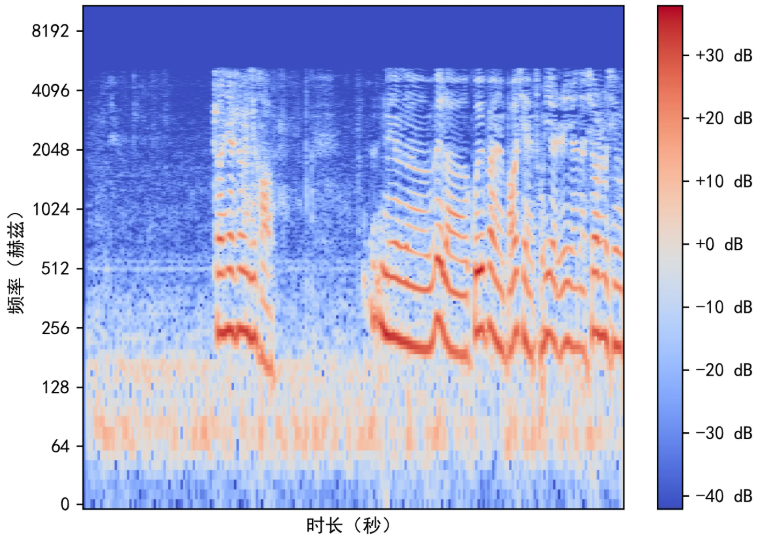 |
|---|---|---|
| 时谱图 | 频谱图 | 语谱图 |
特征工程¶
频域宽度、过零率、MFCC 等。
语音增强¶
谱减法、维纳滤波法、深度学习方法。
语音分类¶
说话人识别:
-
矢量量化 (Vector Quantization, VQ):一种基于聚类的说话人识别方法,通过将语音特征(如 MFCC)映射到预先训练的码本 (codebook) 中的代表性向量,计算测试语音与码本的距离来进行说话人识别。VQ 计算效率高,适用于小规模系统,但对特征变化的鲁棒性较弱,逐渐被更先进的方法取代。
-
高斯混合模型 (Gaussian Mixture Model, GMM):通过多个高斯分布的线性组合对说话人的语音特征分布进行建模(如 GMM-UBM 框架,UBM 指通用背景模型)。测试时,计算语音特征在目标说话人 GMM 和 UBM 上的似然比得分(如 MAP 自适应训练),实现识别。GMM 曾是说话人识别的主流方法,但对长时语音依赖和复杂特征的表征能力有限。
-
深度学习方法:利用深度神经网络(如 DNN、TDNN、ResNet)直接学习说话人的 discriminative 特征(如 d-vector、x-vector),或结合端到端模型(如 ECAPA-TDNN、Speaker Transformer)。深度学习方法通过大规模数据训练,显著提升了短语音和跨场景的识别鲁棒性,成为当前说话人识别的核心技术。
情感分类:
- TODO
语音转文本¶
语音转文本 (Speech To Text, STT) 技术。
-
基于动态时间规整 (Dynamic Time Warping, DTW):一种非参数化方法,通过动态对齐不同长度的语音和参考模板的时间序列,计算最小距离匹配,适用于小词汇量、孤立词的语音识别。
-
基于隐马尔可夫模型 (Hidden Markov Model, HMM):利用统计概率模型对语音信号的时序变化进行建模,通常结合高斯混合模型 (Gaussian Mixture Model, GMM) 进行特征分布拟合,曾是大词汇量连续语音识别的主流方法。
-
深度学习方法:采用深度神经网络(如 RNN、CNN、Transformer 等)端到端地学习语音特征与文本之间的映射,大幅提升了识别准确率,成为现代语音识别(如 ASR 系统)的核心技术。
文本转语音¶
文本转语音 (Text To Speech, TTS) 技术。
A Survey on Neural Speech Synthesis | MSRA - (arxiv.org)
-
梁瑞宇, 王青云, 谢跃, 唐闺臣. 现代语音信号处理(Python版)[M]. 北京: 机械工业出版社, 2022. ↩