序列生成(机器翻译)
序列生成常见的任务有:机器翻译、文本摘要、智能问答等。本文以「机器翻译」为引,展开 Seq2Seq 架构、Attention 机制和 Transformer 模型。
机器翻译基本概念¶
任务定义¶
机器翻译任务定义为:给定源语言,通过建立翻译模型,将其翻译为目标语言。
数据集¶
常见的机器翻译的数据集有 WMT 系列数据集,其他用于机器翻译的数据集可以参考 paper with code 1 中的内容。
以 WMT 2014 EN-DE 为例,其被划分出约 4.5M 个文本对作为训练集,3k 个文本对作为验证集,3k 个文本对作为测试集。文本对示例如下:
评价方法¶
BLEU、ROUGE。
传统方法¶
由于 \(p(x)\) 是已知的,根据乘法原理,可以将原来的建模方式等价于为 \(p(x\mid y)\cdot p(y)\),其中 \(p(x\mid y)\) 是反向翻译模型,\(p(y)\) 是语言模型,统计机器学习方法需要分别训练这两个模型。
Seq2Seq 架构¶
2015 年,Stanford NLP 实验室在 EMNLP 上发表了一篇名为 Effective Approaches to Attention-based Neural Machine Translation 2 的文章,其介绍了一种基于 RNN 的神经网络翻译模型,开启了神经机器翻译的时代。
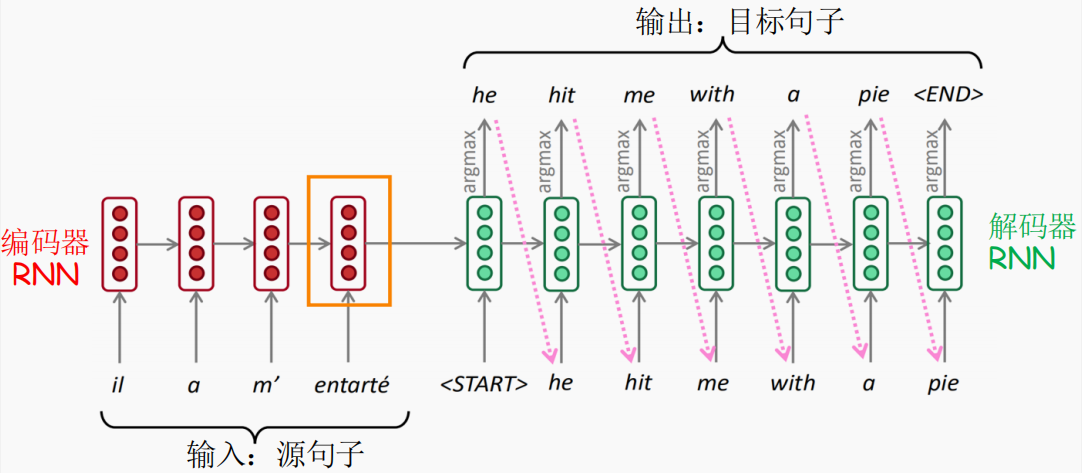
Encoder 部分¶
利用任意一种模型将输入语句编码为「单一」向量 \(h_0\)。
Decoder 部分¶
在使用 RNN 作为解码器时,训练和测试阶段的模型输入是不一样的:
- 训练阶段:隐藏状态的输入不取决于上一个时间步的输出,而是正确答案对应的单词,这种训练模式叫做 Teacher Forcing。当然为了更好的和推理模式衔接,可以将上一个时间步的输出按照一定的比例与正确答案进行组合作为隐藏状态的输入;
- 测试阶段:隐藏状态的输入一定是上一个时间步的输出。
上述基于上一个状态预测下一个状态的模式被称为自回归 (auto-regression) 模式。
上述测试阶段的解码器每一步只选择当前最优的输出,这种贪心策略显然不一定是最优的,为此研究人员提出了 beam search 策略。具体地,其含有一个超参数 \(K\),在编码阶段,保存每一个隐藏状态的前 \(K\) 个最优预测单词,之后就按照 \(K\) 叉树的形式基于前一个状态生成的 \(K\) 个输出得到 \(K \times K\) 个输出,以此类推。最后按照某种度量标准选择所有输出序列中最优的那一条即可。
Attention 机制¶
基于 RNN 的 seq2seq 模型架构(引入了 Attention 机制)如下图所示:
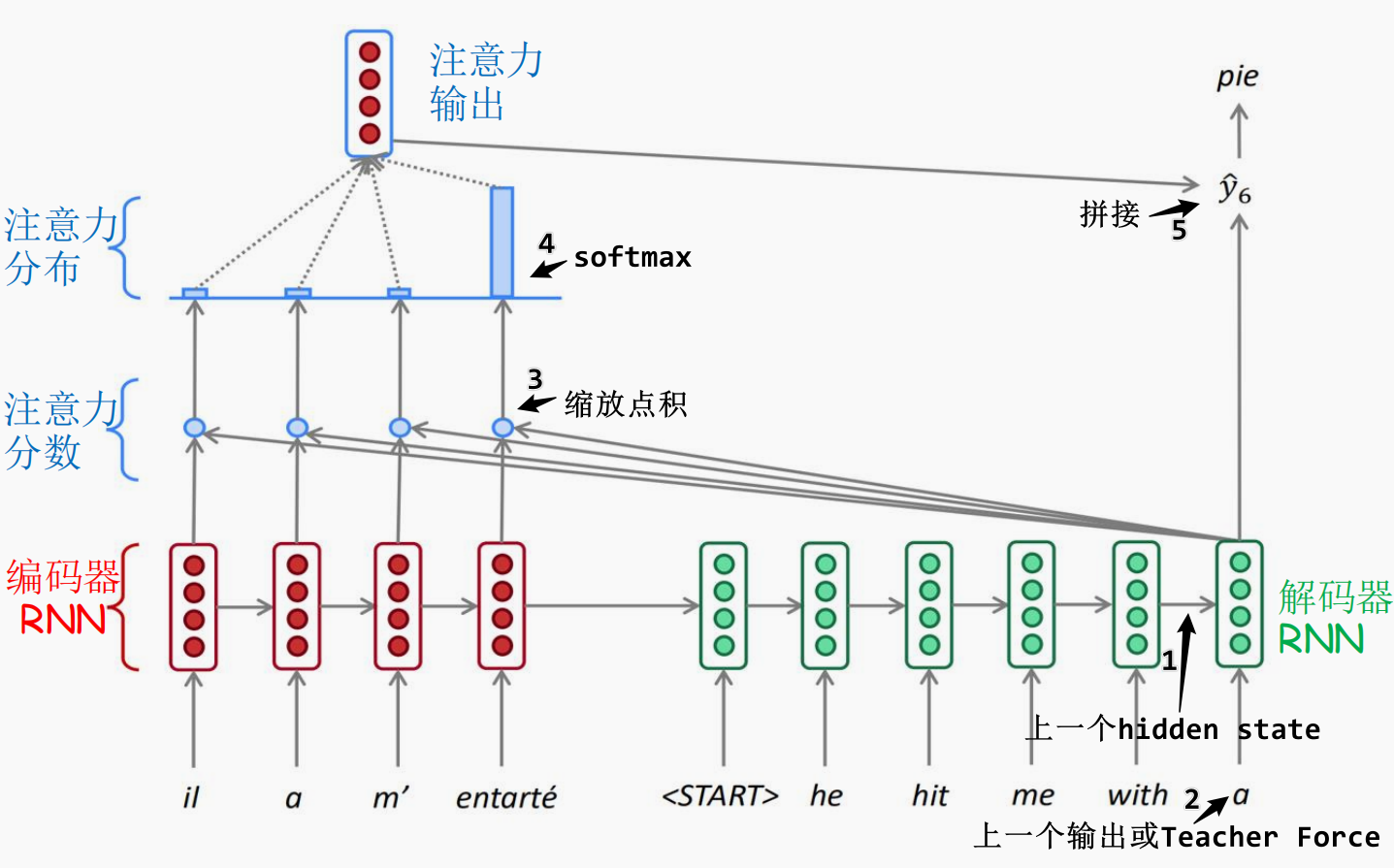
引入 Attention 机制的 seq2seq 模型结构和基本的 seq2seq 模型结构基本一致,只不过在解码时增加了一个注意力权重。具体地:
- 将编码器的所有隐藏输出作为全局 values;
- 在解码时将每一个时间步的隐藏输出作为 query 并和预先存储的 values 计算注意力权重(缩放点积,keys 用 values 表示);
- 接着使用 softmax 计算得到每一个 values 的权重;
- 最后将加权后的向量表示与 query 交互计算后得到当前时间步的输出,同时作为下一个时间步的输入。
该方法有如下几点好处:
- 翻译效果更好:通过使用注意力机制,模型可以学习到全局关系,并且缓解了梯度消失问题,从而提升了翻译的效果;
- 可解释性更好:相较于统计方法的硬对齐方法(只有对应与不对应),使用注意力机制其实就算一种软对齐(按照权重对应)。由于每一个时间步都可以计算每一个输入 token 与所有输入 token 之间的是注意力权重,那么就可以算出一个对齐矩阵,该矩阵完全是模型根据数据学习到的对齐结果。
上述思路都是针对单一句子进行的,如果涉及到更大规模的语料,就需要对注意力的计算方法进行一定的魔改。
Transformer 模型¶
2017 年,Google 团队发表在 NeurIPS 上的一篇 Attention is all you need 3 替换了上述 RNN 结构,解决了 RNN 不能并行计算的问题。模型结构如下图所示:
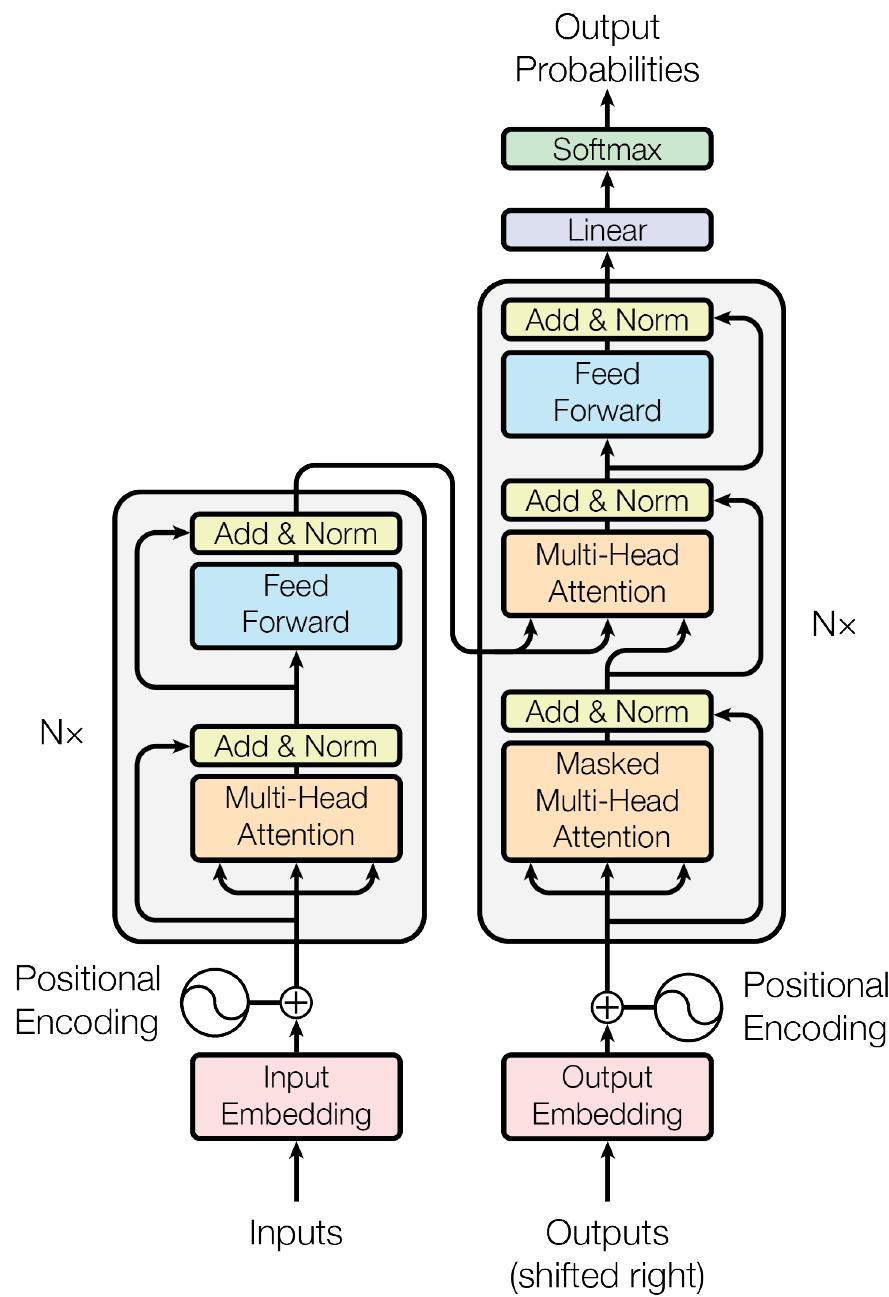
怎么解决不能并行问题的呢?核心就两个思路:
- 引入位置编码。不再逐 token 输入,通过给文本嵌入位置信息,直接输入一整个句子;
- 完全的注意力计算。不再逐 token 传递信息,全部换成注意力机制并行计算。
其中位置编码比较简单,核心在于 Transformer 的注意力计算策略,共有「多头注意力、多头掩码注意力、多头交叉注意力」这三种注意力,前两种注意力由于数据来自同一处,也叫自注意力。下面将按照数据流动的逻辑分别介绍。
Encoder 部分¶
由「多头注意力」和「前馈网络」两部分组成:
- 多头注意力部分:将「源语言嵌入 + 位置嵌入」分成多个头分别计算注意力,之后把多个头的注意力拼接起来,后接残差连接并层归一化;
- 前馈网络部分:将「多头注意力拼接起来的结果」经过两层全连接层进行非线性映射,同样后接残差连接并层归一化。
Decoder 部分¶
由「掩码多头注意力」、「交叉多头注意力」和「前馈网络」三部分组成:
- 掩码多头注意力与上述以 RNN 为基座的方式相同,只不过由于现在可以并行计算,那么就需要掩盖住模型不该知道的后文;
- 交叉多头注意力使用的 K、V 数据源自编码器的表示结果,Q 为解码器的表示结果。解码时每一次的结果可以采用最后一次编码的结果,也可以是相同迭代次数下的编码结果;
- 最后同样输入到前馈网络进行非线性映射。
总结与展望¶
以 RNN 为基座的优缺点分析:
- 缺点:可解释性差、可控性差、因数据产生偏见、上下文保持困难、对训练集的规模要求高、对未见数据泛化性能差;
- 优点:训练模式下可以结合上一个时间步输出。
以 Transformer 为基座的优缺点分析:
- 缺点:训练模式不能结合上一个时间步的输出,这会产生暴露偏差 (Exposure Bias)。计算量大、对显存的需求大、需要额外编码位置信息;
- 优点:计算速度快、可解释性好。
当然,随着 2022 年 ChatGPT 的横空出世,机器翻译的研究范式已经发生了翻天覆地的变化,同理,NLP 的研究范式也发生了很大的改变,感兴趣的读者可以移步 大模型专栏 作进一步的了解。