预训练
本章介绍预训练任务的工作范式。
基本概念¶
TODO
动态词向量¶
TagLM¶
ELMo¶
Peters et al. Deep contextualized word representations. NAACL. 2018. arxiv
编码器架构¶
BERT¶
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2019. arxiv
RoBERTa¶
2019,参数量和 BERT 齐平。基于 Bert 进行了如下修改:
- 更大的 batch size ,训练数据更多,训练时间更长;
- 动态掩码机制 (未用于中文版本)。将数据输入时才 masking,并将训练数据复制多份,一条数据可以进行不同的 masking,划分进不同的 epoch,充分利用数据;
- 删除下一句预测(NSP)任务,认为太简单,对模型序列无益;
- 文本编码采用一种在 word-level 和 character-level 之间的表示
Yinhan Liu et al. Roberta: A robustly optimized BERT pretraining approach, 2019. arxiv
ALBERT¶
ALBERT = A Lite BERT,轻量版 BERT,2019 年提出。有以下特点:
- 对词嵌入参数进行因式分解,降低词嵌入的维度;
- 跨层参数共享,直接减少参数量;
- 句子顺序预测 (Sentence-order prediction, SOP) 取代 NSP,增加任务难度。
Lan et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, 2019. arxiv
ELECTRA¶
Objective: replaced token detection (RTD):判断 token 是替换过的还是原来的。模型会从所有输入标记中学习,而不仅仅是 mask 部分,使计算更有效率。生成器和判别器共同训练,但判别器的梯度不会回流到生成器。
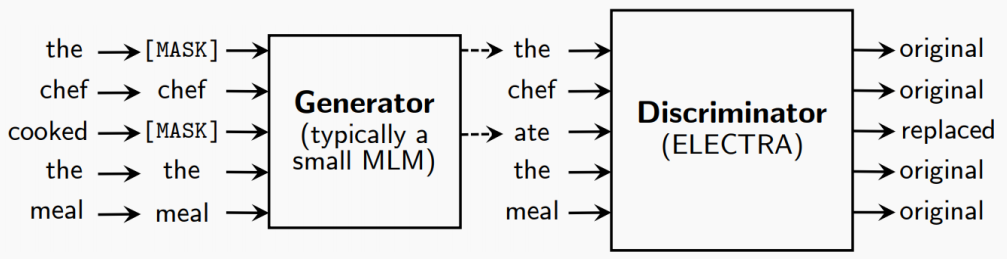
Clark et al. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. 2019. arxiv
编码器 + 解码器架构¶
BART¶
Bidirectional and Auto-Regressive Transformers,由 Meta 于 2019.10 提出:
- 具备完整的编码器和解码器,比 BERT 更适合做生成任务;
- 比纯 decoder 多了双向上下文语境信息。
Lewis et al. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. 2020. arxiv
T5¶
Text-to-Text Transfer Transformer,由 Google 于 2019.10 提出:
- Encoder-Decoder 结构;
- 预训练任务是掩码语言模型:可能 mask 多个连续 token,输出被 mask 的序列,而非完整序列。
Raffel et al. Exploring the limits of transfer learning with a unified text-to-text transformer. 2020. arxiv
解码器架构¶
GPT