聚类学习
本章我们学习一个经典的无监督学习方法:聚类。即通过某种规则将数据集划分为不同的簇。我们将会首先学习样本的距离计算规则,接着从结果论的角度学习如何评估一个聚类结果的好坏,最后按照类别介绍几个具体的聚类算法。
基本概念¶
距离度量¶
聚类的本质就是「根据样本之间的距离将距离相近的样本认定为同一个类别」,因此聚类的关键就是定义样本之间的距离计算准则。不同种类的属性有不同的计算方法,对于关系型数据,有以下几种属性:
- 定性。二元属性、标称属性、序数属性;
- 定量。即数值属性。区间数值可以取负数,比率数值取不了负数。
标称属性。我们在实际计算两个样本标称属性的距离时,一般为了便于计算需要对其进行编码,然后再比较两个样本的所有标称属性中相同或相异的编码个数占总标称属性的数量。常见的标称属性有:籍贯、学历等等。编码方法如下:
| 编码方法 | 适用情况 | 主要优点 | 主要缺点 |
|---|---|---|---|
| One-Hot Encoding | 类别较少 | 无序、通用 | 维度高 |
| Label Encoding | 类别有序 | 简单高效 | 存在隐含数值关系 |
| Binary Encoding | 类别较多 | 低维、高效 | 仍有些许顺序关系 |
| Hash Encoding | 超大类别 | 维度可控 | 可能哈希冲突 |
| Embedding Encoding | 深度学习 | 可学习关系 | 训练成本高 |
二元属性。与标称属性类似同样需要进行编码,但会取决于二元属性的对称性。
| i\j | 1 | 0 | 合计 |
|---|---|---|---|
| 1 | m | n | m+n |
| 0 | p | q | p+q |
| 合计 | m+p | n+q | b |
假设两个样本在二元属性上的取值情况如上表所示:都取 \(1\) 的数量为 \(m\),都取 \(0\) 的数量为 \(q\),取 \((1,0)\) 的数量为 \(n\),取 \((0,1)\) 的数量为 \(p\)。则有以下距离计算公式:
- 对称二元属性。距离为 \(\dfrac{p+n}{m+n+p+q}\)。常见的对称二元属性有:朋友、配偶;
- 非对称二元属性。距离为 \(\dfrac{p+n}{m+n+p}\),因为两个取值都为 1 的情况比取值都为 0 的情况更有意义。常见的非对称二元属性有:上下级、父母与子女、教师与学生。
数值属性。对于两个数值型的样本 \(\boldsymbol x\) 和 \(\boldsymbol y\),定义了以下两种距离度量指标:
-
闵可夫斯基距离。取值范围为 \([0,+\infty]\)。\(h = 1\) 为曼哈顿距离,\(h = 2\) 为欧氏距离,\(h = \infty\) 为切比雪夫距离(上确界距离)。如下式:
\[ \begin{aligned} \text{闵可夫斯基距离:}& d(\boldsymbol x,\boldsymbol y) = \| \boldsymbol x - \boldsymbol y \|_h \\ \text{曼哈顿距离:}& d(\boldsymbol x,\boldsymbol y) = \| \boldsymbol x - \boldsymbol y \|_1 \\ \text{欧几里得距离:}& d(\boldsymbol x,\boldsymbol y) = \| \boldsymbol x - \boldsymbol y \|_2 \\ \text{切比雪夫距离:}& d(\boldsymbol x,\boldsymbol y) = \| \boldsymbol x - \boldsymbol y \|_\infty = \max(\boldsymbol x - \boldsymbol y) \end{aligned} \] -
余弦距离。取值范围为 \([0, 2]\)。就是两个样本的余弦值的相反数加 1 (这很巧妙的利用了余弦值进行了相似性度量并且还确保了计算结果的非负性)。这个度量方法偏向于语言上描述两个对象的差异性,并不适合进行度量测量 (Metric Measure),因为其不具备三角不等式关系。如下式:
\[ d(\boldsymbol x,\boldsymbol y) = 1 - \cos < \boldsymbol x,\boldsymbol y> \]
序数属性。使用排名法对属性的每一个可能的取值进行编码,然后归一化到 \([0,1]\) 范围内,最后就可以使用上面的数值属性的方法进行两个样本的距离度量。
混合属性。如果出现了不止一种上述类别的属性,可以采用「加权平均」的方式进行距离度量。
性能度量¶
一来是进行聚类算法的评估,二来也可以作为聚类算法的优化目标。分为两种,分别是外部指标和内部指标:
外部指标。所谓外部指标就是已经有一个“参考模型”存在了,将当前模型与参考模型的比对结果作为指标。我们考虑两两样本的聚类结果,定义下面的变量:
显然 \(a+b+c+d=m(m-1)/2\),常见的外部指标如下:
- JC 指数:\(\displaystyle JC = \frac{a}{a+b+c}\)
- FM 指数:\(\displaystyle \sqrt{\frac{a}{a+b} \cdot \frac{a}{a+c}}\)
- RI 指数:\(\displaystyle \frac{2(a+d)}{m(m-1)}\)
上述指数取值均在 \([0,1]\) 之间,且越大越好。
内部指标。所谓内部指标就是仅仅考虑当前模型的聚类结果。同样考虑两两样本的聚类结果,定义下面的变量:
常见的内部指标比如:轮廓系数。
基于划分的聚类算法¶
Kmeans 及其变种都只适用于 凸形状 的样本分布。
K-means¶
目标函数定义为:
K-means 算法流程大体上可以归纳为三步:
- 随机选择 \(k\) 个样本作为聚类中心(\(k\) 为超参数);
- 遍历所有样本,将每个样本划分到距离(欧氏距离或其他距离度量方法)最近的聚类中心,每个类别记作一个簇;
- 更新 \(k\) 个簇的中心为簇中所有样本的均值。
重复上述迭代过程直到算法收敛。达到以下任意一种条件即表示算法收敛:
- 损失函数小于阈值;
- 达到最大迭代次数。
假设样本数量为 \(N\),簇的数量为 \(K\),最大迭代轮数为 iter,则 K-means 算法的时间复杂度为 \(O(\text{iter} \times NK)\)。
K-means++¶
此法相对于 K-means 做出了一个小的改进。在一开始选择 k 个聚类中心时,并不是随机初始化 k 个,而是首先随机出 1 个,然后循环 \(k-1\) 次选择剩下的 k-1 个聚类中心。选择的规则是:每次选择最不可能成为新的聚类中心的样本,或者是到所有聚类中心的最小距离最大的样本。
Bisecting K-means¶
此法叫做二分 K-means 算法。具体的,在一开始将所有的样本划分为一个簇,然后每次选择一个误差最大的簇进行二分裂,不断分裂直到收敛。这种方法不能使得 Loss 最小,但是可以作为 K-means 算法的一个预热,比如可以通过这种方法得到一个相对合理的簇中心,然后再利用 K-means 算法进行聚类。
K-mediods¶
目标函数定义为:
即 K 中心点算法。例如 PAM 算法,其使用实际的样本作为簇中心而不是用均值众数等新点作为簇中心。具体的,对于每一个簇中心 \(O_i\),随机选择一个非簇中心的样本 \(O_{\text{random}}\),如果用 \(O_{\text{random}}\) 替换 \(O_i\) 之后损失减小,则替换,否则继续迭代直到算法收敛。
基于层次的聚类算法¶
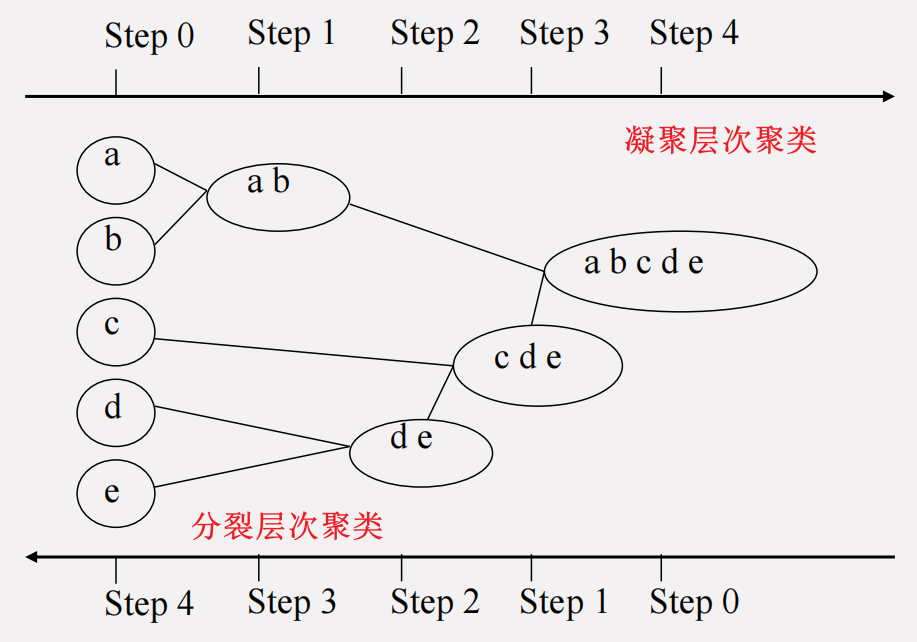
主要介绍簇之间的距离度量方法以及凝聚方法 (Agglomerative, AGNES) 和分裂方法 (Divisive Analysis, DIANA)。两种算法可以形象的表述为下图:
簇之间的距离度量:
- 单链(Single-linkage):簇之间的邻近度定义为不同簇中两个最近的样本的距离;
- 全链(Complete-linkage):簇之间的邻近度定义为不同簇中两个最远的样本的距离;
- 均链(Average-linkage):簇之间的邻近度定义为不同簇中所有样本之间距离的均值;
- 质心距离(Distance between centroids):簇之间的邻近度定义为不同簇的质心之间的距离。
AGNES¶
凝聚算法有点类似于并查集,初始时每一个样本点都是一个簇,不断合并最接近的两个簇直到达到需要的簇数量就停止合并。而这里簇之间的距离就按照上面介绍的簇之间的距离度量来实现。
不同邻近度方法下凝聚层次聚类对比:
| 单链 | 全链 | 均链 | 质心距离 | |
|---|---|---|---|---|
| 优点 | 可以处理非椭圆形的簇 | - | 簇间的距离不易受到噪声或异常值的影响 | 簇间的距离不易受到噪声或异常值的影响 |
| 缺点 | 聚类结果对噪声或异常值敏感 | 倾向于分裂较大的簇 | 倾向于形成球形的簇 | 倾向于形成球形的簇 |
DIANA¶
分裂算法有点类似于 Bisecting K-means,每次选一个簇根据某种规则将其分类为两个簇,直到达到需要的簇数量就停止分裂。
基于密度的聚类算法¶
DBSCAN¶
基于密度的带噪声空间聚类(Density-Based Spatial Clustering of Application with Noise, DBSCAN)
其实,就是一个朴素 dfs。算法定义为:
- 每次随机选择一个没有访问过的对象开始 dfs;
- 如果发现无法成为核心对象,即邻域 \(\epsilon\) 内的样本数量小于 \(\text{Minpts}\),则标记为 visited 并重新选点;
- 如果可以成为核心对象,则形成一个簇 C 并将当前邻域内没有归属的样本全都纳为 C 的样本,并以这些新纳入的样本为起点递归的拓展,直到无法拓展新的样本。
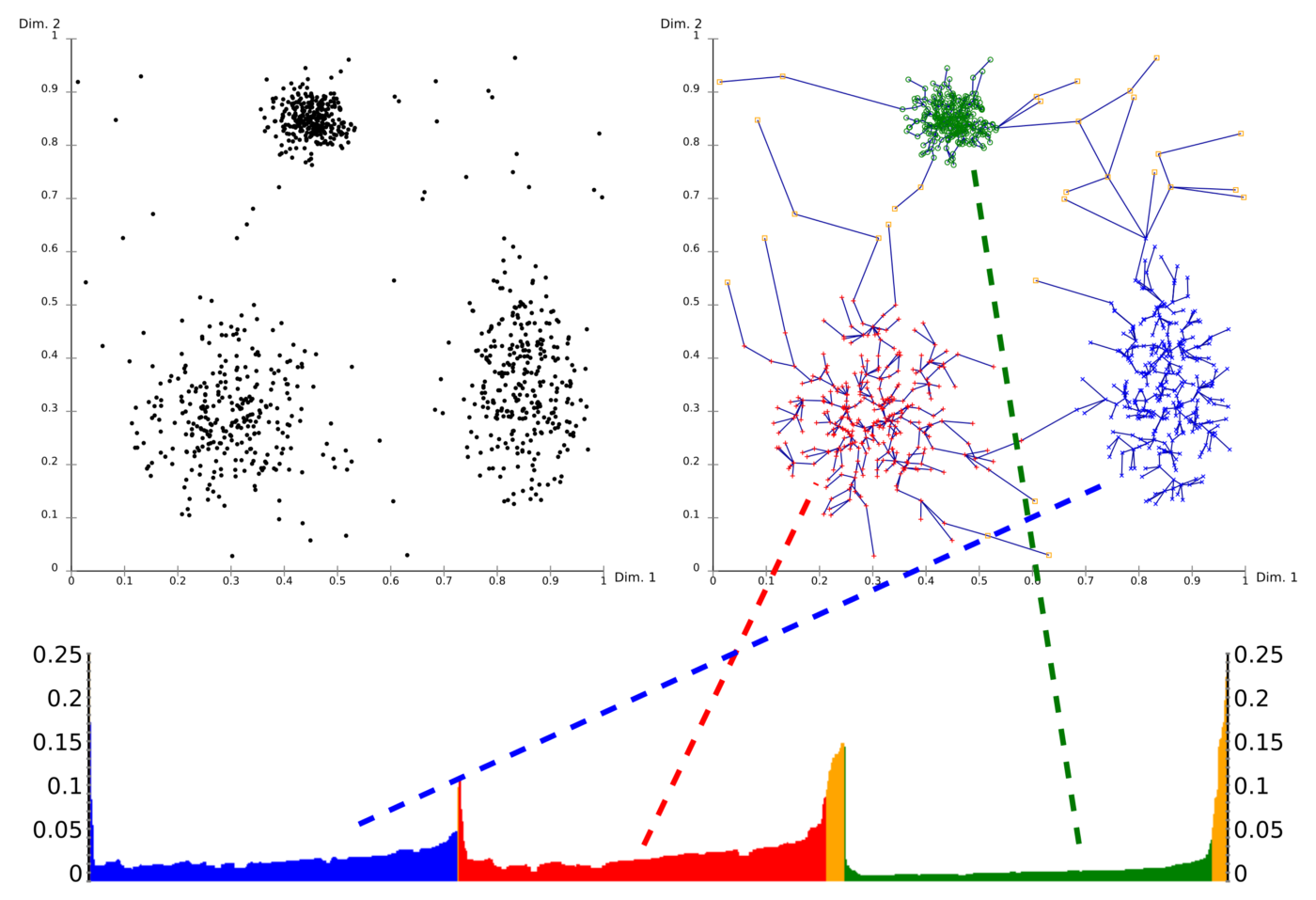
基于密度的 DBDSAN 聚类算法可以适应更加复杂的数据分布场景,但是缺点在于对超参数 (\(\epsilon,\text{Minpts}\)) 很敏感。并且由于超参数是二维联合的,因此如何调参 (\(\epsilon,\text{Minpts}\)) 是一个很困难的事。在此基础之上,提出 DBSCAN 算法的团队又提出了其改良版本:OPTICS 算法。
OPTICS¶
用于确定聚类结构的排序点聚类(Ordering Points To Identify the Clustering Structure, OPTICS)
基于密度的 OPTICS 算法延续了 DBSCAN 的策略,只需要提前设定邻域内最少样本数量 Minpts 而不需要提前设置邻域大小 \(\epsilon\)。有两个关键的概念定义:
- 核心距离:样本成为核心对象的最小半径阈值;
-
可达距离:对于两个样本 p 和 q,其中 q 是核心对象,可达距离定义为:
\[ \max{(q \text{ 的核心距离}, p \text{ 与 } q \text{ 的距离})} \]
最终可以得到一个按照某种规则排序的以及其可达距离。此时可以自行划分邻域的值进而按照预期进行聚类而不会像 DBSCAN 一样不受控制。OPTICS 的演示效果如下所示: