视频理解
本文介绍以视频为单位的视频理解任务。
动作识别¶
基本概念¶
任务定义。定义时序长度为 \(T\) 的视频 \(X =\{ x_1, x_2, \cdots , x_T\}\),其中 \(x_i\) 表示第 \(i\) 帧图像。定义动作标签集合 \(c\in C\),其中每个 \(c\) 表示一个动作类别。动作识别 (Action Recognition) 任务可以看作是一个分类问题 1,其目标是找到一个映射函数 \(f: X \to C\),将 \(X\) 映射到 \(C\) 中的一个标签。
数据集。如下图所示:

评价指标。主要有以下两点:
- Clip Hit@k:从视频中提取多个片段 (clip) 并独立预测,统计所有 clip 的 Top-k 准确率;
- Video Hit@k:将视频的多个 clip 的预测结果进行聚合,统计所有 video 的 Top-k 准确率。
*注:Top-k 表示模型输出 \(k\) 次的结果中是否存在正确答案,因此我们平时常说的准确率其实是 Top-1 指标。
传统方法¶
一种做法是将图像的特征融合为视频的特征 2 ,直接的融合方式可分为早期融合 (Early fusion)、晚期融合 (Late fusion) 和缓慢融合 (Slow fusion) 三种,如下图所示:
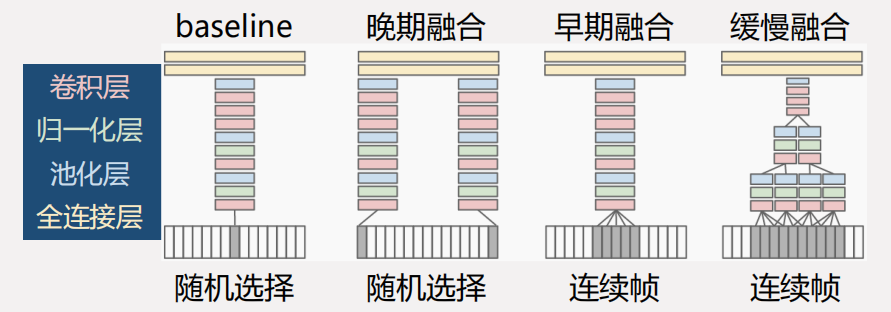
得到的实验结果如下所示(将视频当图像的 Single-Frame 如下红框,三种融合如下绿框):
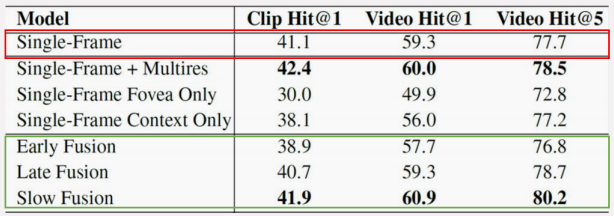
缓慢融合方式在网络内部逐渐融合相邻帧的信息,取得了最好的效果。但融合了时序信息的效果并没有显著优于基于静态图像的效果,说明基于 2D 卷积的网络难以有效提取运动信息。
双流网络¶
让模型捕捉不同帧之间的关系需要引入物体运动的信息,人们定义了光流 (Optical flow) 来量化物体的运动信息。
光流的定义与 Lucas Kanade 算法。光流可以简单地理解为视频帧中每一个像素点的二维速度,那么一个 \(w\times h\) 的视频帧就需要存储 \(w\times h\times 2\) 个光流信息。Lucas Kanade 在 1981 年提出了稠密光流的计算方法 3,尝试计算光流信息。
记空间中任意一点 \((x,y,t)\) 的亮度 (luminance) 为 \(I(\cdot)\),在 \(\delta t\) 的时间间隔内,空间中的点的位移量为 \(\delta x,\delta y\),并且假设在这段时间间隔中亮度保持不变,即:
根据泰勒公式,我们将上式右边展开为微分近似的形式(忽略高阶无穷小),即:
其中 \(I_x,I_y,I_t\) 即像素点在三个维度上的变化量。联合上两式,有:
我们记像素点在 \(x\) 方向的速度为 \(u\),在 \(y\) 方向的速度为 \(v\),那么将上式同除 \(\delta t\) 就有:
实际求解的过程中,\(I_x,I_y,I_t\) 可以根据相邻两帧的亮度信息直接求解,因此上式只有 \(u\) 和 \(v\) 两个未知量,只需要构造两个或以上数量的等式约束即可求解。论文中继续做了一个假设,即认为邻域内像素点的光流变化是一致的。不妨假设邻域大小为 \(n\times n\),则有:
我们将上式简记为:
由于 \(n^2>2\),因此上式是一个超定方程。我们使用最小二乘法求解这个超定方程可以得到:
要求 \(A^TA\) 是可逆的。
网络结构。双流网络 (Two-stream convolutional network) 4 结构如下图所示:

实验结果如下所示:

实验结果表明:
- 基于手工特征的 IDT 在当时取得了最高的准确率;
- 缓慢融合方式距离 IDT 差距明显;
- 双流网络的效果虽然弱于 IDT,但是充分验证了深度学习用于视频动作识别的可行性。
3D 卷积网络¶
由于光流信息需要提前计算并存储,导致开销较大,人们开始尝试使用 3D 卷积来完成动作识别任务。

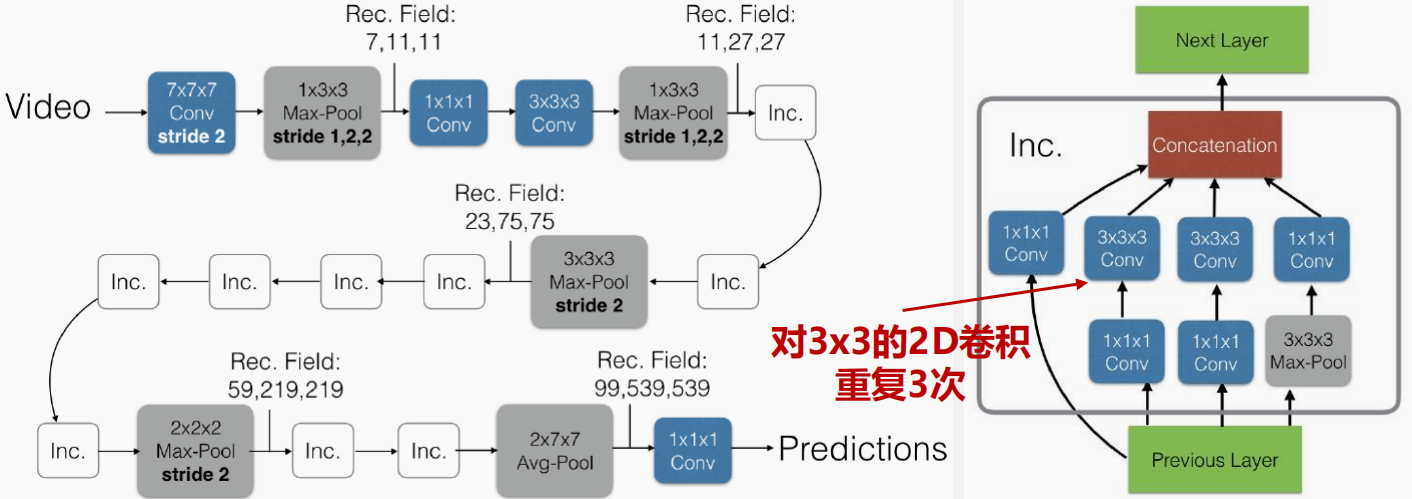
C3D。C3D 5 直接将 VGG 的卷积操作从 \(3\times 3\) 拓展到了 \(3\times 3\times 3\) 进行 3D 卷积,在 Sport-1M 数据集上进行训练。模型架构如下图所示:

C3D 实验结果如下所示:

可以看到 C3D 的效果要略好于缓慢融合网络,同时如果让 C3D 在更大的数据集上预训练,再进行微调,则可以取得更好的效果。但 C3D 的训练时间非常长,难以继续拓展。
I3D。I3D 6 提出了膨胀 3D 卷积 (Inflated 3D convolution),并融合了预训练 + 引入光流的操作。模型架构如下图所示:
I3D 的实验结果如下所示:

可以看到在最大的预训练模型的基础上,加上双流信息以及膨胀 3D 卷积的 I3D 性能达到了 SOTA。但是似乎没什么意义,因为就和前文提到的那样,计算和存储代价太大了。但至少证明了膨胀 3D 卷积是有用的。
Transformer 网络¶
TimeSformer 7 是第一个尝试将 ViT 8 引入到动作识别任务的工作。如何将应用于 2D 图像的 ViT 迁移到视频领域的动作识别任务?
Note
ViT Workflow:
类似于之前的工作,TimeSformer 对于如何将 ViT 拓展到视频数据进行了大量的探索:

实验结果如下所示:

用 Transformer 的好处:
- Transformer 的全局建模能力使得相关模型能够更好地利用时序上下文信息,更易于应用到长时序的视频;
- 相较于 CNN「局部性、平移不变性」的归纳偏置 (Inductive Bias),以及 RNN「时序依赖性」的归纳偏置,Transformer「注意力机制」的归纳偏置更弱,更易于拓展成多模态模型。
时序任务¶
这里简单介绍一下时序任务。
时序动作检测¶
任务定义。假设数据集 \(X\) 中包含 \(N\) 个视频,表示为 \(X=\{X_i\}_{i=1}^N\),其中每个视频对应一个监督信息 \(y_i\):
- 训练阶段,利用视频和对应的监督信息使模型能够准确识别每个类别的动作模式;
- 测试阶段,模型根据输入的无修剪视频,给出时序动作检测结果。第 \(i\) 个视频的预测结果表示为 \(p_i=\{t_j^s,t_j^e,c_j,s_j\}_{j=1}^M\),即模型给当前视频预测出了 \(M\) 个动作,其中 \(t_j^s,t_j^e,c_j,s_j\) 分别表示第 \(i\) 个视频中第 \(j\) 个动作的开始时间、结束时间、动作类别和置信度。
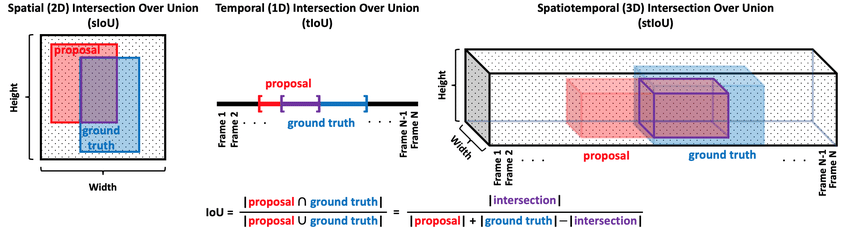
评价指标。与目标检测类似,时序动作检测也可以采用平均精度均值 (mean Average Precision, mAP) 作为评价指标。与目标检测的 mAP 略有不同,这里的 IoU 变成了 tIoU。各种 IoU 的计算方法如下图所示:
时序动作分割¶
任务定义。假设数据集 \(X\) 中包含 \(N\) 个视频,表示为 \(X=\{X_i\}_{i=1}^N\),其中每个视频对应一个监督信息 \(y_i\):
- 测试阶段,模型根据输入的视频,给出时序动作分割结果。第 \(i\) 个视频的预测结果表示为 \(p_i=\{p_j\}_{j=1}^F\),即模型给当前共 F 帧的视频中的每一帧都预测出了一个类别,其中 \(p_j\) 表示第 \(i\) 个视频的第 \(j\) 帧的动作类别。
对比分析¶
时序动作检测与时序动作分割主要有以下不同:
- 时序动作检测的视频中,动作一般比较稀疏,模型需要有识别背景的能力。常见的应用有:监控检测(只关注有人且有行为的片段)、体育赛事分析(只关注运动员运动的片段)等;
- 时序动作分割的视频中,动作一般都很密集,模型需要逐帧分类。常见的应用有烹饪视频逐帧分类、手术视频逐帧分类等。
-
Video Analysis 相关领域解读之 Action Recognition | 林天威 - (zhuanlan.zhihu.com) ↩
-
Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014: 1725-1732. ↩
-
Bruce D. Lucas and Takeo Kanade. 1981. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th international joint conference on Artificial intelligence - Volume 2 (IJCAI'81). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 674–679. ↩
-
Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[J]. Advances in neural information processing systems, 2014, 27. ↩
-
Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 4489-4497. ↩
-
Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6299-6308. ↩
-
Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding?[C]//ICML. 2021, 2(3): 4. ↩
-
轻松理解 ViT (Vision Transformer) 原理及源码 | 000_error - (zhuanlan.zhihu.com) ↩