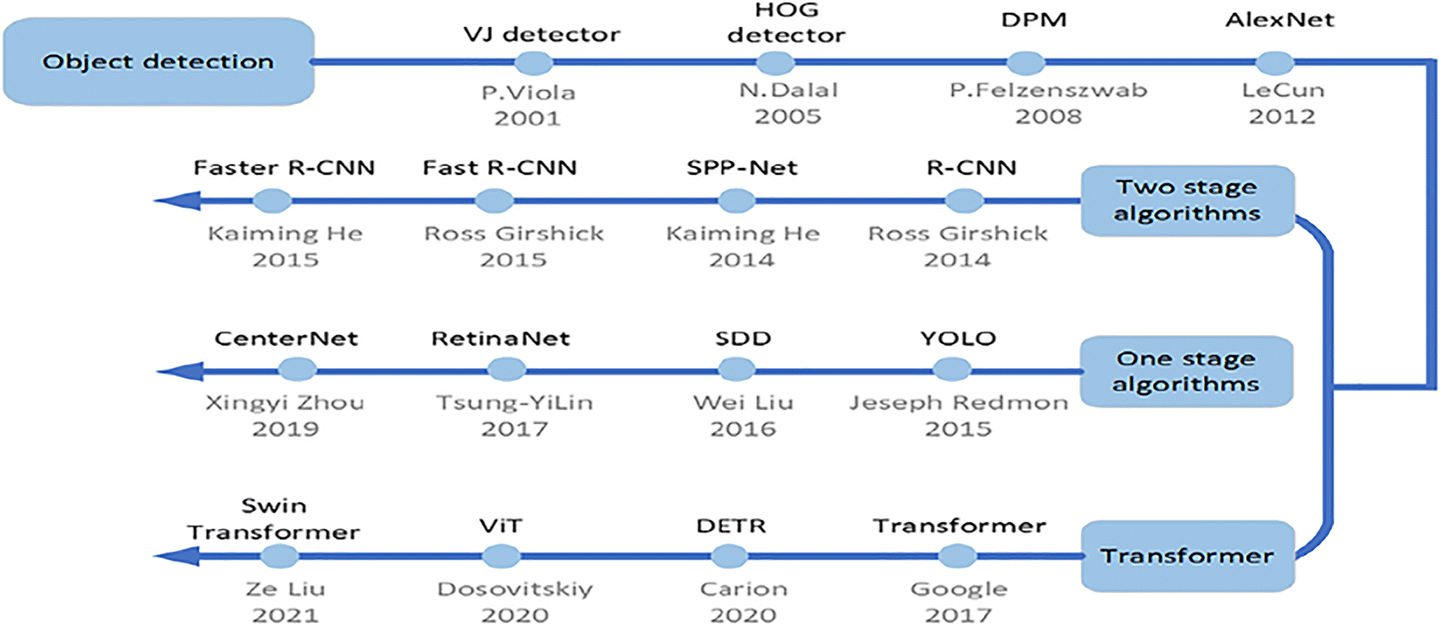
目标检测
本章介绍目标检测 (Object Detection) 任务 1 2。目标检测可以分解为「定位 + 分类」两个子任务。分类任务在上一章 图像分类 已详细介绍,此处我们重点关注定位任务。

基本概念¶
各种框¶
框有各种称呼,比如:真实框(人工标注的框)、预测框(算法预测的框)、锚框(以某个像素为中心生成的框),这些框可以统称为边界框。但无论哪种说法,本质上就是一个包裹对象的矩形边界罢了。一个框一般可以用以下两种方式定义:
- 中心点坐标 \((x,y)\) 与框的宽 \(w\) 与高 \(h\),用四元组表示为 \((x,y,w,h)\);
- 左上角的点坐标 \((x_1,y_1)\) 与右下角的点坐标 \((x_2,y_2)\),用四元组表示为 \((x_1,y_1,x_2,y_2)\)。
交并比¶
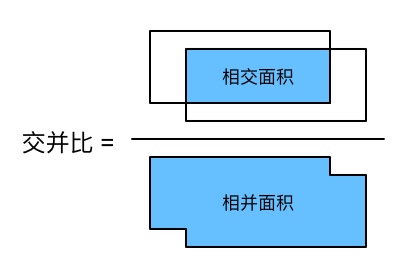
为了量化预测框和真实框之间的差异,定义了交并比 (Intersection over Union, IoU) 的计算方法:
非极大值抑制¶
在对一张图像进行目标检测时,模型可能会输出很多预测框,为了简化输出,我们需要筛选出最合适的预测框,为此我们引入非极大值抑制 (non-maximum suppression, NMS) 算法。
定义:模型预测的边界框列表为 \(L\),每个边界框都有对应的置信度。算法输入:检测框及其置信度列表 \(L\)、IoU 阈值 \(T\),算法输出:最终的检测框及其置信度列表 \(L'\)。于是 NMS 算法流程就是:
- 给 \(L\) 按置信度降序排序;
- 取出 \(L\) 中置信度最大的边界框 \(B_i\),枚举剩余所有的预测框 \(B_j\ (j\neq i)\),从 \(L\) 中去除与 \(B_i\) 的 IoU 超过阈值 \(T\) 的所有边界框(也就是所谓的抑制了非极大值);
- 重复步 \(2\) 直到所有边界框都被遍历到,返回 \(L\) 得到最终的边界框及其置信度输出 \(L'\)。
性能度量¶
目标检测任务需要人为预先标记边界框 (ground-truth bounding box) 作为真实框,从而量化模型的性能。综合性比较强的度量指标为精度均值 (Average Precision, AP),其中的四个组成部分与二分类的混淆矩阵类似,只不过定义略有不同:
- TP:预测框与真实框的 IoU 达到了阈值、预测类别与真实类别相同;
- FP:预测框与真实框的 IoU 没达到阈值、预测类别与真实类别相同;
- FN:没有被匹配的真实框数量;
- TN:不包含目标的预测框数量(这类数量很多,一般不看)。
AP 就是 P-R 曲线 下的面积,最后可以给所有类别的 AP 取一个均值得到平均精度均值 (mean Average Precision, mAP)。
Tip
传统目标检测方法是:滑窗提取图像中指定规格的所有区域,然后通过各种算子提取特征,最后送到机器学习分类器中完成检测任务。这种方法不光速度慢,精度也低,逐渐被深度学习方法取代。接下来按照「两阶段、单阶段和基于注意力」三个角度分别介绍对应的基于深度学习的目标检测方法。
两阶段目标检测¶
所谓两阶段,主要由以下两部分组成:
- 提取候选区域 (Region of Interest, RoI);
- 对候选区域进行分类,同时进行回归来修正边界框位置。
Seletive Search¶
为了解决滑窗法产生的大量冗余边界框,选择性搜索 (Seletive Search, SS) 算法被提了出来。其核心思想就是邻域聚合,即对「相邻相似度高」的区域不断聚合直到达到指定的聚合数量。
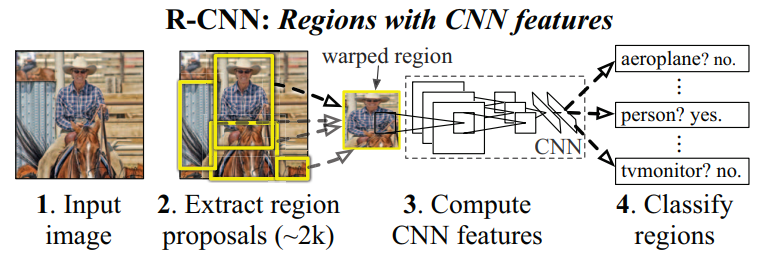
R-CNN¶
R-CNN (Region-CNN) 3 结合了传统方法和深度学习方法,推理过程为:
- 使用 SS 算法提取 2000 个区域候选 (Region of Interest, RoI);
- 将区域候选调整至固定尺寸,利用 CNN 计算每个区域候选的特征;
- 使用 SVM 分类,利用回归算法预测 x 和 y 方向的偏移量,高度和宽度的缩放值;
- 使用 NMS 处理重复的检测框。
R-CNN 主要有以下两个缺点:
- 将候选区域调整到指定大小会导致图像失真,导致模型泛化能力下降;
- 每张图像都要用 CNN 提取 2000 个候选区域的特征,这导致计算量过大。
SPP-Net¶
为了解决输入图像尺寸受限的问题,SPP-Net 4 提出了空间金字塔池化 (Spatial Pyramid Pooling, SPP) 的网络层。
SSP-Net 推理过程如下:
- 使用 SS 算法提取 2000 个区域候选;
- 利用 CNN 计算图像的特征,计算每个区域候选的位置,得到候选区域的特征;
- 使用 SVM 分类,利用回归算法预测 x 和 y 方向的偏移量,高度和宽度的缩放值;
- 使用 NMS 处理重复的检测框。
可以看出 SPP-Net 相较于 R-CNN,其实就一个创新点:可以接收不同尺寸的图像。为了解决这个问题,其核心工作就是利用空间金字塔池化的方法,一次卷积得到所有候选区域的特征(文中证明了原始图像和特征图像的位置是对应的)。
Fast R-CNN¶
SPP-Net 还是有多阶段的缺点,Fast R-CNN 5 应运而生。其最大的创新点就是:将每一个 RoI 的特征调整到同样的大小,然后展平送到全连接层同时进行分类和回归得到类别概率和框的位置。
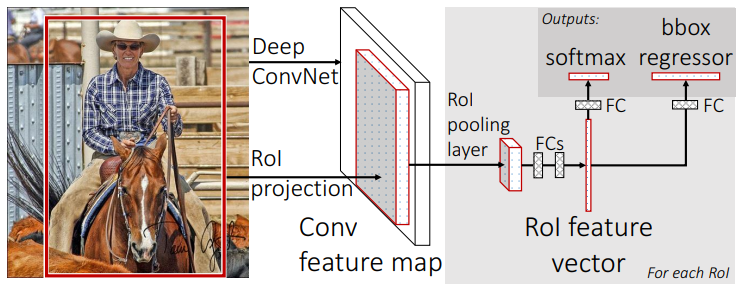
模型的训练损失是分类和回归的加权结果,对于一张图像的一个候选区域,其得到的损失如下:
其中 \(p\) 表示候选区域的预测标签,\(u\) 表示候选区域的真实标签,\(u\geq 1\) 表示当且仅当类别预测正确才会加上预测框的位置损失,\(t^u\) 表示预测的边界框位置,\(v\) 表示真实的边界框位置(均使用中心点和 \(\log\) 边长来表示)。
分类损失如下:
位置损失如下:
其中魔改的 \(L_1\) 正则化损失如下:
这种回归损失相较于 \(L_2\),在预测偏差较大时 (\(\lvert x \rvert\ge1\)) 不会出现梯度爆炸的问题,因为 \(\nabla L_2=x\),而 \(\nabla \text{smooth}_{L_1}=\pm 1\)。
Faster R-CNN¶
Fast R-CNN 的瓶颈在 SS 算法提取 RoI 上,为了解决这个问题,Faster R-CNN 6 7 被提了出来。
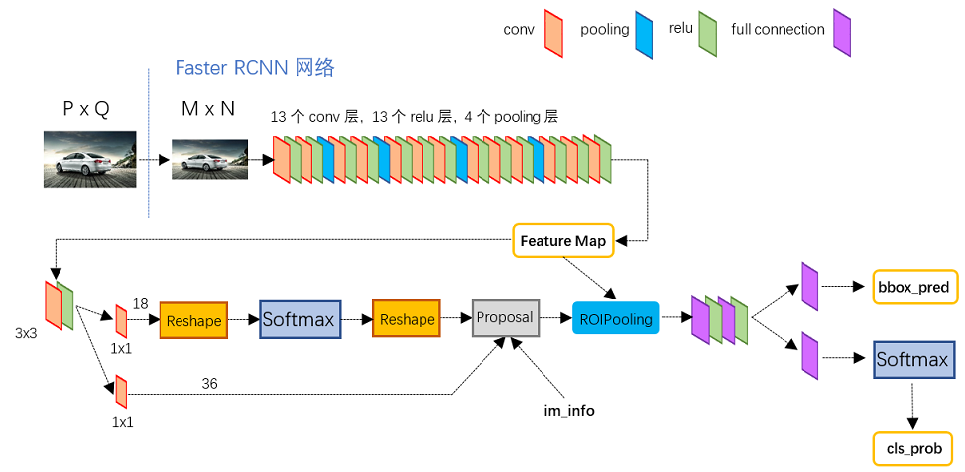
Faster R-CNN 提出了区域候选网络 (Region Proposal Network, RPN) 来替代 SS 算法。RPN 主要有两个特点:
- 提出了锚点的概念:特征图中的「一个元素」都对应了原始图像的「一个感受野区域」,该区域的中心像素称为锚点 (Anchor) ,以锚点为中心按一定的纵横比 (ratio) 和尺度 (scale) 绘制的框称为锚框 (Anchor box);
- 贡献了模型训练的一部分损失来源。其需要对锚点生成的所有锚框进行二分类,判断是前景还是背景(对应二分类交叉熵损失),如果是前景就又产生回归损失。
单阶段目标检测¶
上述介绍的算法都分为了「寻找候选区域」和「判定候选区域」两部分,即使 Faster R-CNN 已经可以实现端到端的训练了,但是还是分成了两个网络进行训练。接下来介绍一个网络就实现目标检测的模型,也就是所谓的单阶段。
YOLO¶
我们重点关注 YOLO v1 版本的网络模型。
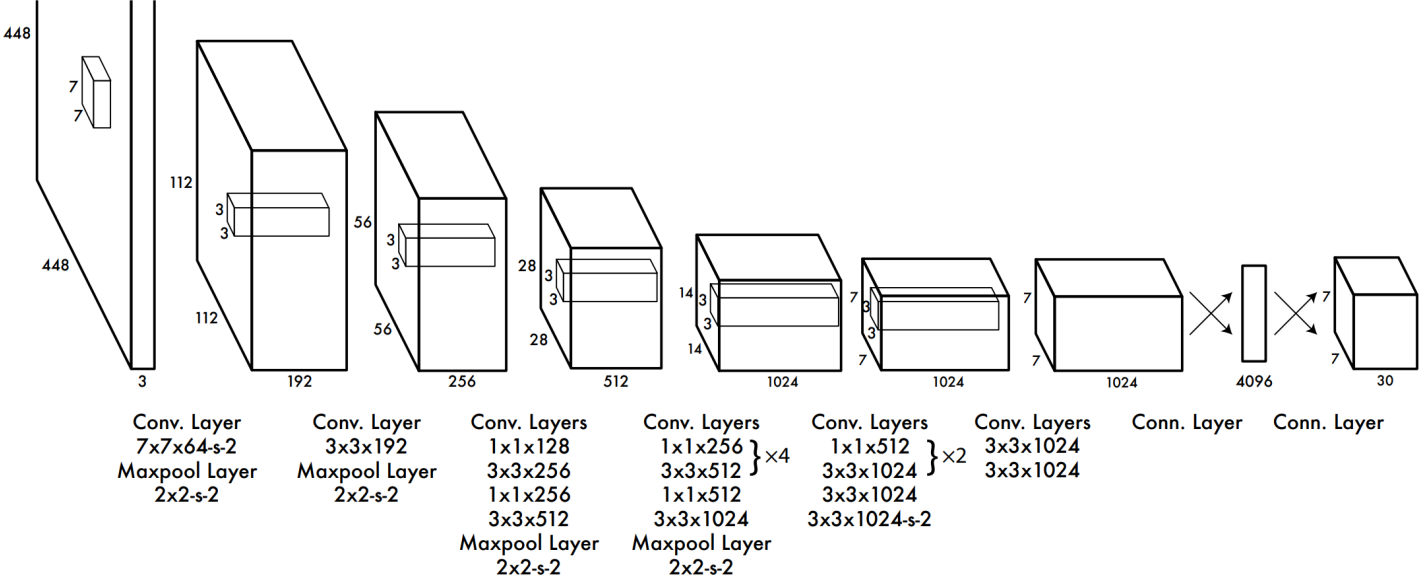
模型损失。解释一下最后输出的 \(7 \times 7 \times 30\) 的张量。该模型在 VOC 2007 上进行的训练与测试,该数据集有 \(20\) 个类别。YOLO v1 算法给每一个网格生成 \(2\) 个检测框,每一个检测框用 \([x,y,w,h,c]\) 共 \(5\) 个变量来表示,分别表示检测框的位置和检测框的置信度(用 IoU 来量化)。因此最后输出的 \(30\) 维的通道中,前 \(10\) 维就是两个检测框共 \(10\) 个变量,后 \(20\) 维表示网格包含类对象的条件概率。因此最后就变成了一个回归问题:
分别解释上式中的损失:
- 第一行即带有目标的中心点位置回归损失;
- 第二行即带有目标的预测框的边长回归损失;
- 第三行即带有目标的概率损失;
- 第四行即不带目标的概率损失;
- 第五行即带有目标的条件类别概率损失。
YOLO v1 的模型特点如下:
- 优点:检测速度快,完全达到了实时检测的效果;可以实现端到端的方式训练网络;
- 缺点:每个网格只对应一个类,所以目标密集或目标较小时,检测效果不佳;定位的误差较大,导致精度不如双阶段目标检测模型。
SSD¶
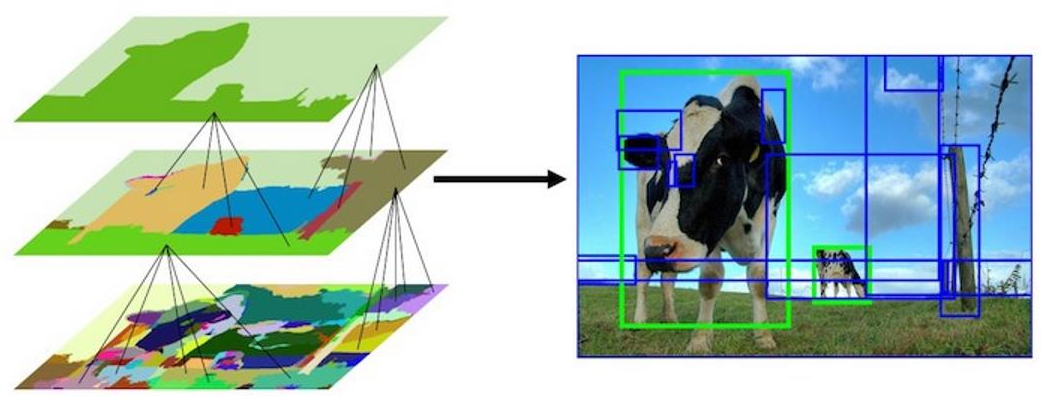
单镜头多框检测 (Single Shot multibox Detector, SSD) 8 通过引入多尺度概念克服小目标检测效果不佳的问题。
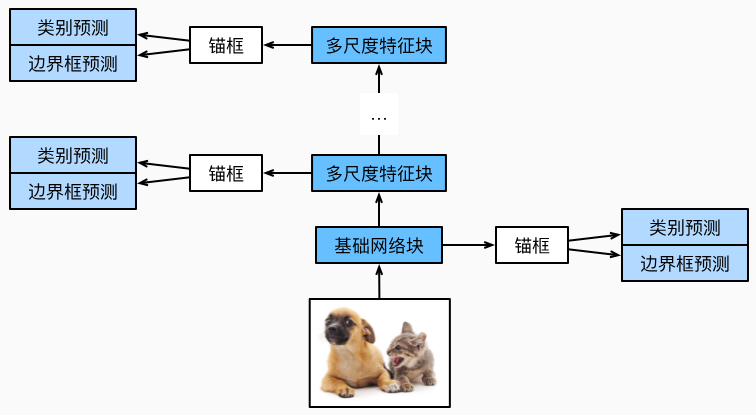
如上图所示,SSD 算法在每一个尺度下都基于对应的特征图进行目标检测任务。与 YOLO 类似,SSD 在每一个特征图上都生成多个默认框并 reshape 得到 \(4+ C + 1\) 维度的向量,其中 4 表示预测框的位置,\(C\) 表示类别数量,\(1\) 表示是否为前景的概率。
模型特点:
- 优点:SSD 几乎适用于任意规则物体的目标检测任务。
- 缺点:SSD 在小物体的目标检测任务上仍差于 Faster R-CNN,作者认为这是因为底层级的卷积得不到较好的特征(深层的已经“看”不到小目标了,就不用说了);大量的参数需要人工设置,比如默认框的大小。
基于 Transformer 的目标检测¶
DETR¶
首篇基于 Transformer 的目标检测算法 9。
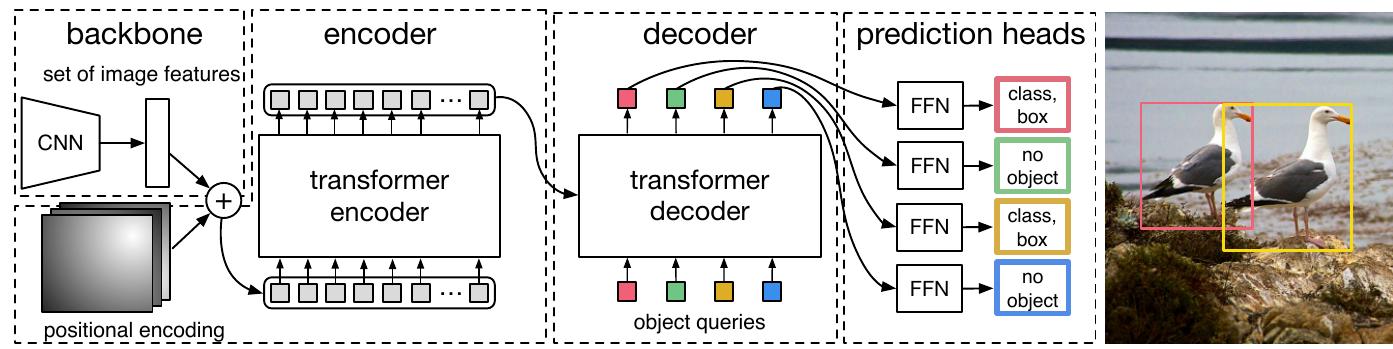
主要由四部分组成:
- 图像表示:使用 ResNet50 进行编码,然后使用余弦相似度进行位置编码;
- Encoder:每层 Encoder 都嵌入了位置编码;
- Decoder:使用 100 个 object 作为 query 让模型进行推理;
- FNN:使用 4 个 FNN 层分别预测位置与类别。
损失函数:使用二分图匹配得到最小匹配损失。损失同样由类别损失和位置损失组成。
模型特点:
- 优点:在较大目标上的检测效果很好;提出了新的目标检测 pipeline,需要更少的先验信息;从图像输入到检测框输出的端到端模型;不需要特别设计的层,易于进一步修改。
- 缺点:框架并不完美,存在收敛速度慢、小目标检测效果差等缺陷。
小目标检测¶
对于小目标 (Small Object) 的判断通常采用以下两种方式:
- 相对小目标:目标的尺寸低于原图尺寸的 \(10\%\);
- 绝对小目标:目标的尺寸小于 \(32\times 32\) 像素(MS-COCO 数据集)。
当小目标的面积小于一定阈值(\(1\) 像素),则失去了检测的意义。
小目标检测任务的难点:1)小目标的视觉表现不明显,可利用信息少,更难提取有效的特征;2)更易受到光照、遮挡、聚集等因素的干扰;3)数据集短缺,常用数据集中小目标的占比不足,导致模型对小目标的泛化能力弱。
针对小目标检测存在的难点,现有小目标检测方法可分为如下几种:
- 从数据入手:把小目标拷贝多份到原始图像上 10;
- 从特征入手:把各个阶段的特征融合到一起 4、针对每一个阶段的特征都训练一个分类回归器 8、基于 GAN 网络将低分辨率图像超分辨并利用上超分辨后的图像特征 11。
开放词汇目标检测¶
YOLO-World 12 借鉴了 CLIP 的跨模态对比学习方法进行预训练,使得下游任务可以进行 zero-shot learning。
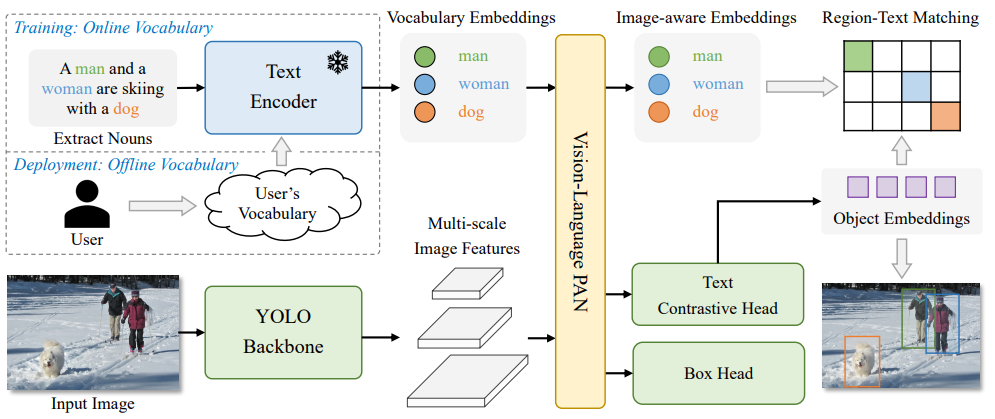
-
A survey: object detection methods from CNN to transformer | MTA 2022 - (link.springer.com) ↩
-
Object Detection in 20 Years: A Survey | IEEE 2023 - (arxiv.org) ↩
-
Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587. ↩
-
He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916. ↩↩
-
R. Girshick, "Fast R-CNN," 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 2015, pp. 1440-1448, doi: 10.1109/ICCV.2015.169. keywords: {Training;Proposals;Feature extraction;Object detection;Pipelines;Computer architecture;Open source software}, ↩
-
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | NeurIPS 2015 - (arxiv.org) ↩
-
Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing, 2016: 21-37. ↩↩
-
Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Cham: Springer International Publishing, 2020: 213-229. ↩
-
Bosquet, Brais, et al. "A full data augmentation pipeline for small object detection based on generative adversarial networks." Pattern Recognition 133 (2023): 108998. ↩
-
Li J, Liang X, Wei Y, et al. Perceptual generative adversarial networks for small object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1222-1230. ↩
-
Cheng T, Song L, Ge Y, et al. Yolo-world: Real-time open-vocabulary object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 16901-16911. ↩