图像分类
本文以图像分类 1 任务为引,展开 CV 界的一些重大突破。
LeNet¶
1998 年,LeCun 提出了用于手写数字识别的 LeNet-5 网络,标志着卷积神经网络的开端:
- 7 层网络,60K 参数量;
- 使用 Sigmoid 激活函数、Average 池化、Softmax 分类器。

AlexNet¶
2012 年,Krizhevsky 在 ILSVR 2012 上提出了 AlexNet 网络:
- 8 层网络,60M 参数量;
- 使用 ReLU 激活函数。
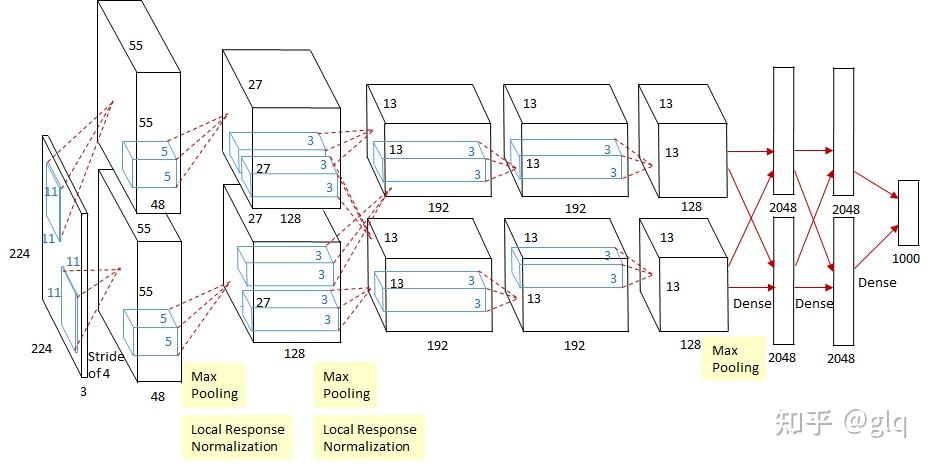
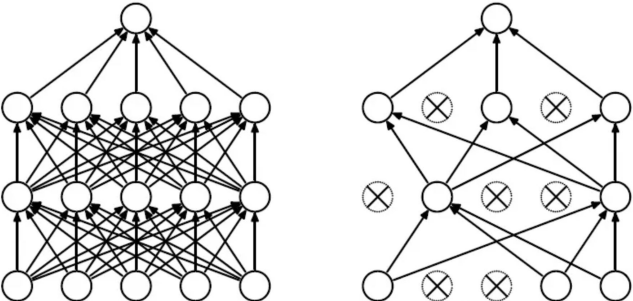
随机失活¶
在全连接层采用随机失活 (dropout) 策略缓解过拟合问题,提升模型的泛化性。
数据增强¶
采用数据增强技术 (data augmentation) 增强数据集,包括翻转 (flipping),裁剪 (cropping),颜色变换 (color changes),避免过拟合问题。

VGGNet¶
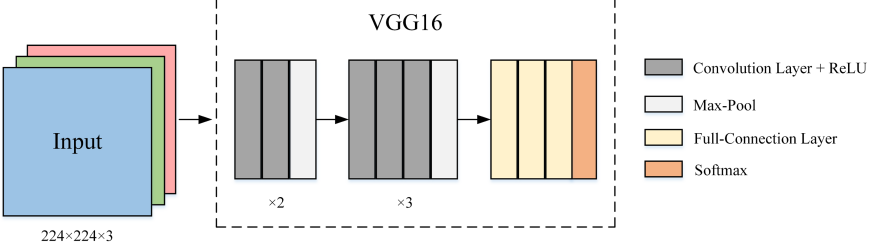
2014 年,牛津大学的视觉几何组 (Visual Geometry Group) 在 ILSVR 2014 上提出了 VGG-16 网络:16 层网络,138M 参数量。
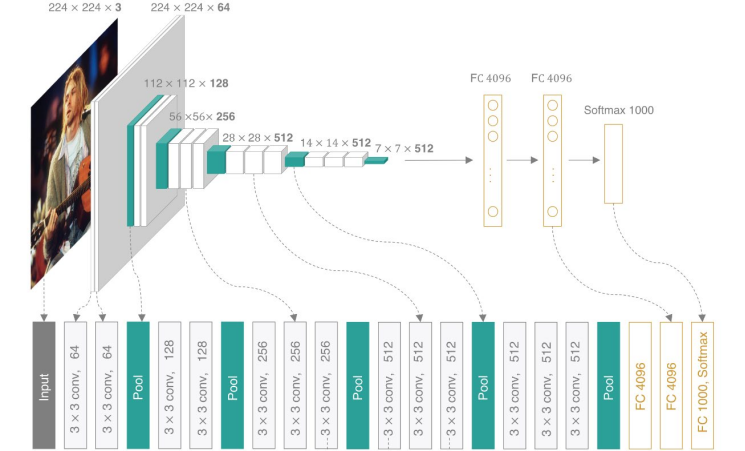
基本模块¶
用基本模块构造网络,这一思想已成为深度卷积神经网络的主要构建方法。
多尺度训练¶
提出了多尺度训练 (Multi-Scale training) 的数据增强方式,在一定范围内随机缩放输入图像,再随机裁剪出 \(224\times 224\) 的训练图像。测试时将全连接层转换为卷积层,避免了测试图像尺寸必须为 \(224\times 224\) 的限制。

LeNet、AlenNet 和 VGGNet 的缺点
LeNet、AlexNet 和 VGGNet 采用相同的思想构建网络,即通过堆叠卷积层提取并融合图像的空间特征,将其展平为一维向量后利用全连接层完成分类。此过程会产生以下问题:1)展平的过程中会丢弃一部分空间信息;2)全连接层的参数量过大。
NiN¶
2014 年,网络中的网络 (Network-in-Network, NiN) 模型解决了上述网络参数量大的问题,将通道特征作为类别判定依据。
点卷积¶
基本模块中首先是常规的卷积,然后紧跟 \(1\times 1\) 的卷积,分类的类别数就是通道数。\(1\times 1\) 卷积又称点卷积,本质就是 2D 场景下参数量最少的等宽卷积,可以理解为通道上的降维策略。
GAP¶
提出全局最大池化 (Global Average Pooling, GAP) 操作,就是将一整个 feature map 取均值得到一个数字。
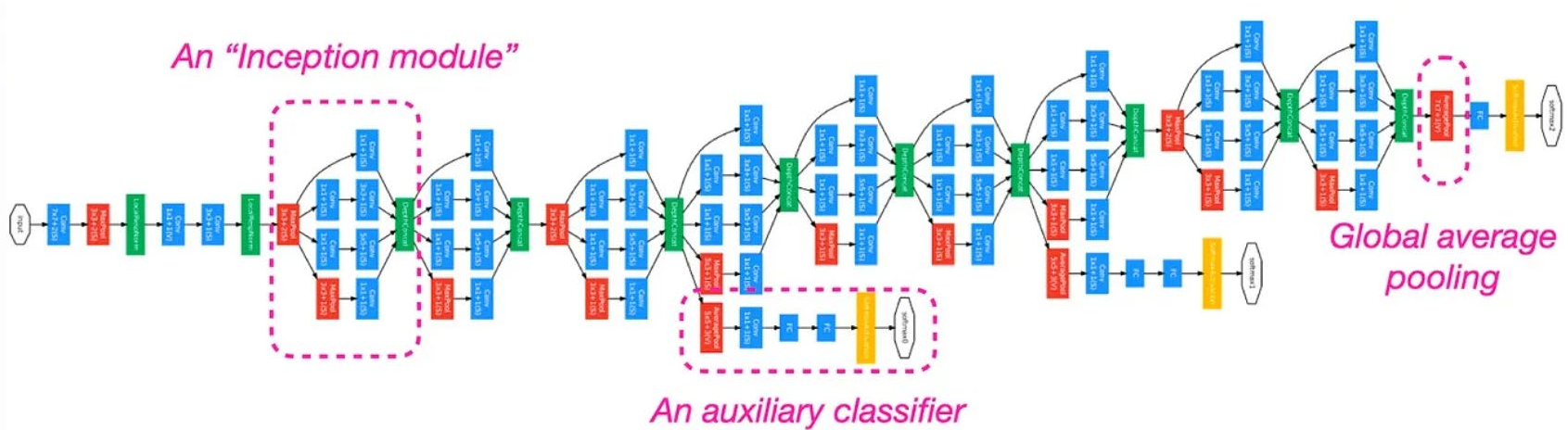
GoogLeNet¶
2014 年,谷歌团队借鉴了 NiN 的思想提出了 GoogLeNet:22 层网络, 6.8M 参数量。
添加了辅助分类器,使用 GAP 代替全连接层,但通道数不等于类别数,所以仍需要一个全连接层:
扩展网络宽度¶
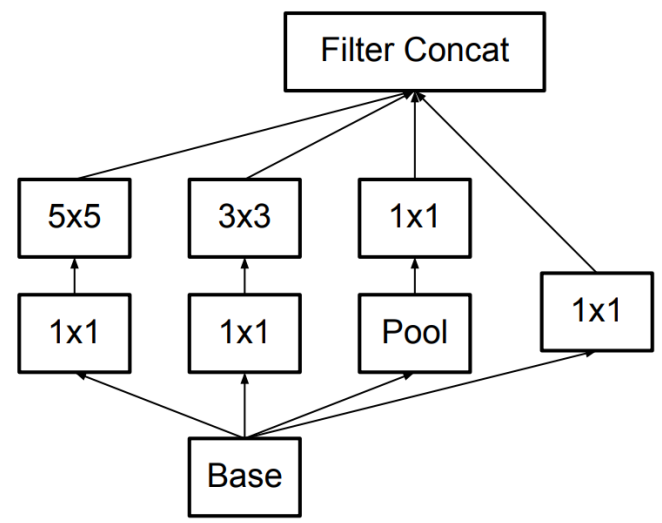
GoogLeNet 希望能够同时在深度和宽度上拓展网络,但是又要避免参数量过大的问题,因此提出了 Inception V1 模块。
Inception V1 的特点为:
- 通过四路并行方式增加神经网络的宽度,提升模型对不同尺度的适应性;
- 利用 \(1\times 1\) 卷积减少通道数,减少参数量。
Inception V1 的后续改进:
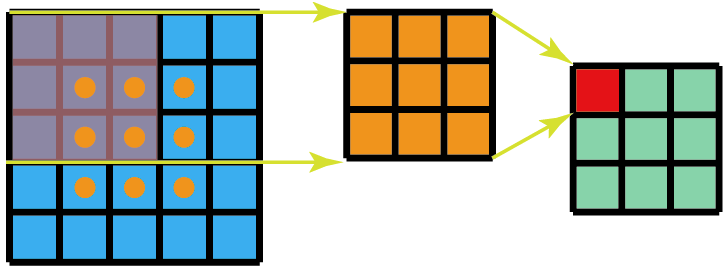
- 空间可分离卷积:将 \(n\times n\) 的卷积核替换成 \(1\) 个 \(1\times n\) 和 \(1\) 个 \(n\times 1\) 的卷积核,减少参数量。前提是 \(n\times n\) 的卷积核是低秩的,这样才能被分解为两个更小核的乘积;
- 并行卷积和池化:并行执行卷积操作(步长为 \(2\))和池化操作,避免表示瓶颈 (Representational Bottleneck) 或计算量过大的问题。
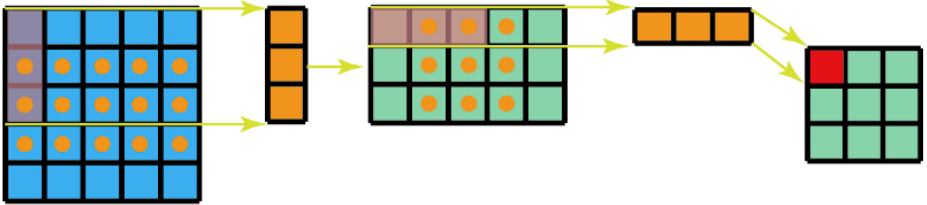
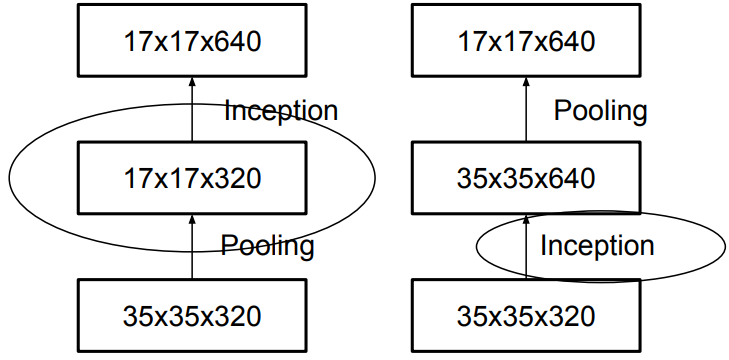
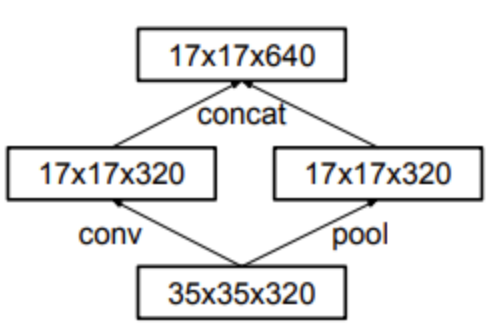
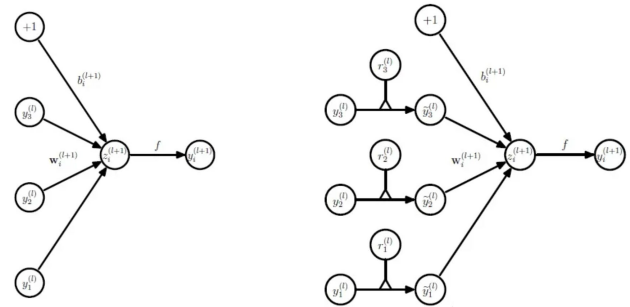
批标准化¶
内部协变量偏移 (Internal Covariate Shift) 问题。神经网络中深层的神经元高度依赖于浅层的神经元,导致深层网络可能一直在适应浅层网络的数据分布变化。该问题可能导致:
- 需要谨慎设置学习速率,使得训练速度更慢;
- 梯度下降过程中可能不稳定,导致收敛困难;
- 受模型初始参数的影响。
为了解决这个问题,同时提高了网络的训练速度,Inception V2 使用批标准化 (Batch Normalize) 策略。训练阶段的批标准化如下图所示,测试阶段使用整个训练阶段的均值和标准差。

其他标准化层:
- Batch norm:对每个 mini-batch 的数据进行归一化处理,常用于图像相关任务;
- Layer norm:对每个样本的所有通道进行归一化处理,常用于处理序列数据;
- Instance norm:对每个样本的每个通道进行归一化处理,常用于风格迁移任务;
- Group norm:对每个样本的每组通道进行归一化处理。
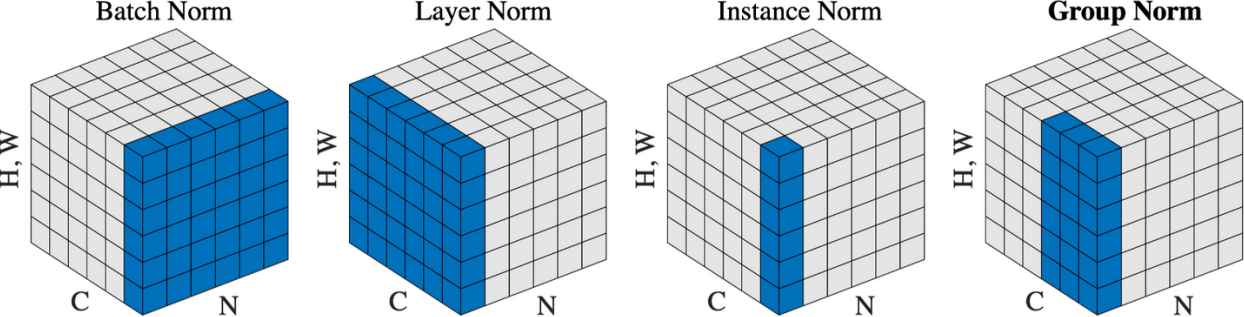
网络退化
大量工作证明,网络越深则性能越强。但是当网络的层数超过 \(20\) 层时,继续加深网络反而会使其性能下降。原因并非过拟合或梯度消失/爆炸,而是 网络退化 (Network degradation)。
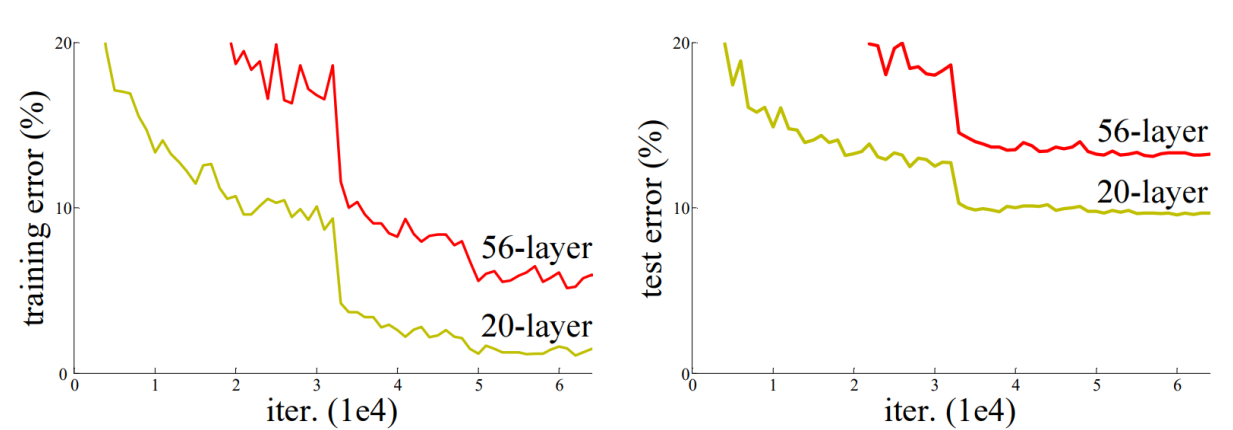 本质原因是神经网络很难学到“恒等映射”,那么更深层的网络一旦失效,就会退化。
本质原因是神经网络很难学到“恒等映射”,那么更深层的网络一旦失效,就会退化。
ResNet¶
梦开始的地方。
残差连接¶
2016 年,何凯明提出的 ResNet 模型引入了残差连接 (Residual Connection) 的概念,让网络深度不再成为约束。其核心思想是让模型学习输入与目标输出之间的残差,而不是直接预测目标输出,这解决了网络深度过大时出现的网络退化问题 2。
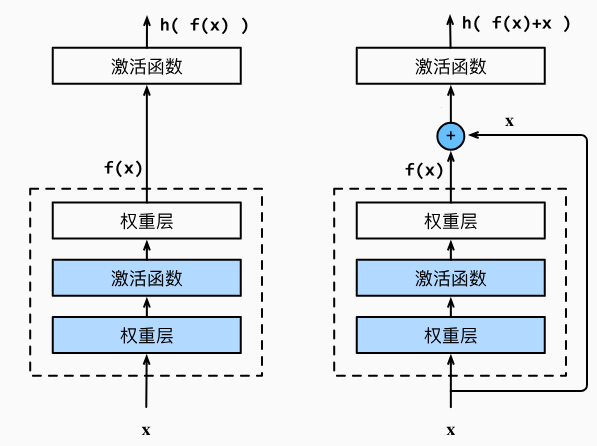
怎么缓解网络退化问题的?由于我们并不知道到底多少层网络才是最合适的,或者哪些层网络是有效的,由于计算代价的问题,我们不可能一个一个试,最好的办法就是让神经网路自己能够“抛弃”掉没有用的网络层。数学形式上,就是希望多出来的网络直接进行形如 \(h(\text{input})=\text{input}\) 的恒等映射。
放在上图中,假设 \(h(\cdot)=\text{ReLU}(\cdot)\),那么左边就是要学习出 \(f(x)=x\) 的映射,右边就是要学习出 \(f(x)=0\) 的映射。想要学习出 \(f(x)=x\) 的映射是不容易的,越深的网络越容易抖动;但学习 \(f(x)=0\) 可太容易了,只要算出来的结果是非正的,那么 \(\mathrm{ReLU}\) 之后就是 \(0\)。好比让你在一张试卷上恰好考 \(80\) 分,你还得掂量掂量,但让你考 \(0\) 分,那简直手到擒来。
通过这种 trick,网络具备了“自动抛弃无用层”的能力,自然也就解决了网络退化的问题。
其实也缓解了梯度消失的问题。这里将流动的数据简记为 \(x\),将每一层的权重和偏置简记为 \(w\),激活函数记作 \(F\),预测损失记作 \(L\),那么带有残差连接的网络数据流动就是:
那么损失传递到第 \(i\) 层对应的梯度就是:
可以看到错误信号可以传递到任意一层,并且还会带有网络中新学习到的知识。
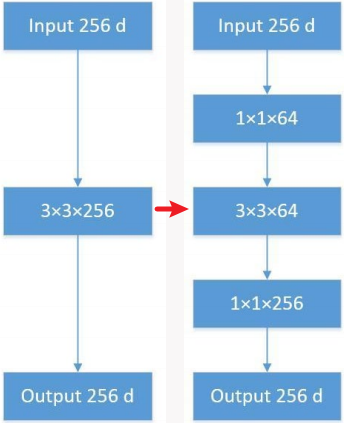
漏斗结构¶
ResNet 模型还引入了类似漏斗的 bottleneck 结构,先压缩再还原,有效减少参数量的同时还能增强模型的表达能力。由以下三部分组成:
- 降维的 \(1\times 1\) 卷积核:减少通道数;
- 常规的 \(3\times 3\) 卷积核:特征融合;
- 升维的 \(1\times 1\) 卷积核:还原通道数。
Attention for CNNs
视觉注意力机制是人类视觉所特有的大脑信号处理机制,更关注视野中感兴趣的信息,而抑制其他无用信息。常见的注意力机制:通道注意力机制 (Channel attention)、空间注意力机制 (Spatial attention)。
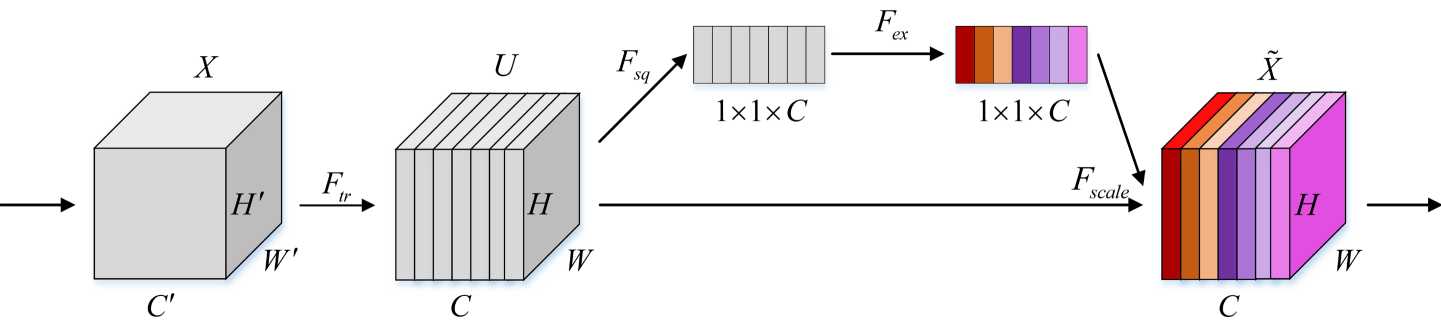
SENet¶
Squeeze-and-Excitation Networks (SENet) 引入了通道注意力机制,利用通道注意力机制使网络关注更重要的通道:
- 压缩 (Squeeze) 模块:利用 GAP 提取每个通道的全局信息;
- 激励 (Excitation) 模块:利用 Sigmoid 函数将全局信息映射到 \((0,1)\) 作为每一个通道的权重;
- 加权:将激励模块输出的权重加权到每个通道的特征。
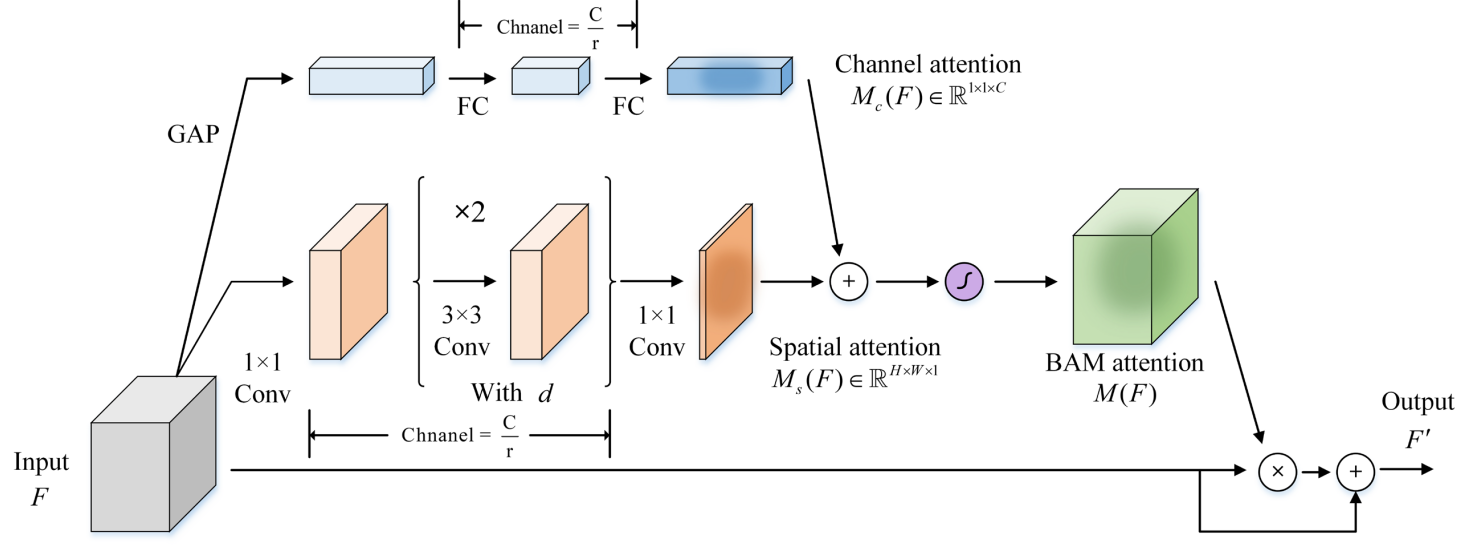
BAM¶
Bottleneck Attention Module (BAM) 同时引入了通道注意力机制与空间注意力机制:
- 通道注意力机制分支:关注更重要的通道;
- 空间注意力机制分支:关注更重要的空间位置。
结合两个注意力机制可以让模型找到特征图中更重要的信息。当然,容易发现这是一个缝合怪,其实就只提出了一个空间注意力机制,缝合了漏斗结构、通道注意力、残差连接。
半监督范式¶
半监督学习定义很清晰,就是结合少量有标记的数据与大量无标记的数据训练模型。

半监督学习的学习准则就是最小化模型在有标签数据和无标签数据上的加权损失,其中有标签数据的损失就是常规的比如 KL 散度、交叉熵等等,关键就是如何定义模型在无标签数据上的损失。关于模型在无标签样本上产生的损失,综述 1 中将其总结为了 5 大类,我们只展开其中的前两个,即「一致性正则化」和「自训练」,具体地:
- 一致性正则化就是最小化「同一张图片的不同增强结果在同一个模型上的输出差异」或/和「同一张图片在不同模型上的输出差异」,衡量差异的方法也可以使用交叉熵、KL 散度、均方误差等;
- 自训练就是给无标签数据生成一个伪标签,然后当全监督学习来做。生成伪标签的方法也有很多,比如最小熵法、协同训练法等等。
MixMatch¶
MixMatch 3 算法流程如下图所示:

首先给一张图片用诸如旋转、混合等方法增强除出了 \(K\) 个版本,加权平均模型的预测结果后,通过最小熵法得到伪标签。
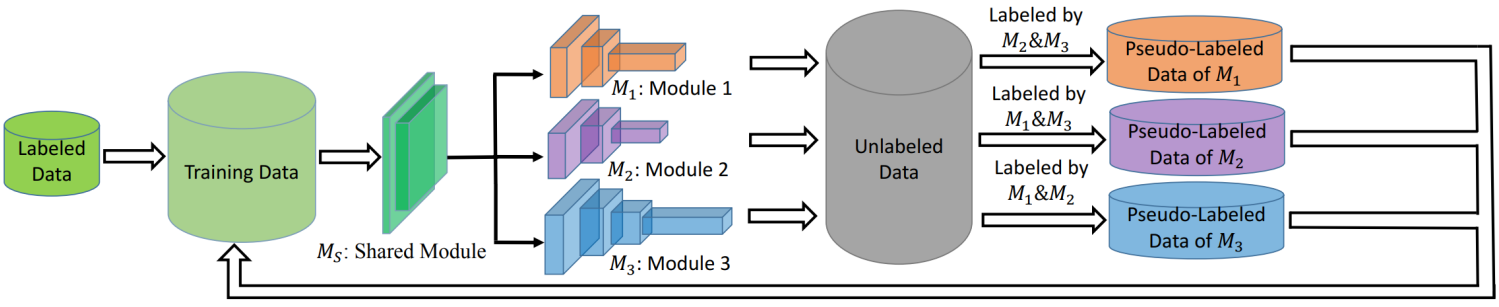
TriNet¶
TriNet 4 是协同训练的一种。将最高置信度的无标签数据打上伪标签作为新的训练数据,循环往复直到收敛。
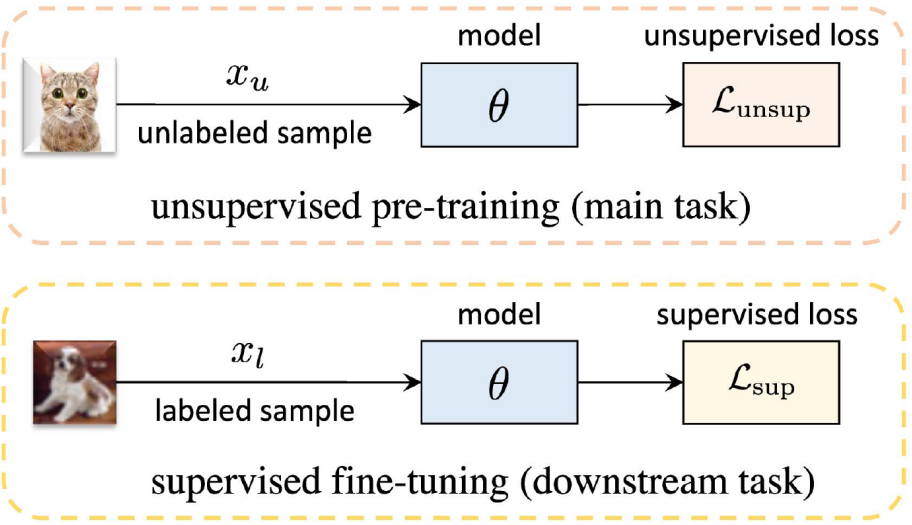
无监督范式¶
无监督图像分类任务本质上是为了学习一个能够高效特征提取的编码器,然后再应用到下游的各种任务(比如图像分类)。所以本节其实是在讨论「预训练任务」。无监督学习的范式如下图所示:
当然,训练的根本是优化模型的损失,在有监督学习任务中,模型的损失很好做,就是预测标签与真实标签之间的差异,在无监督任务中怎么办呢?研究者们想出了各种方法来构造损失,常见的比如「自监督学习」、「对比学习」、「深度聚类」等等,无论哪种方法,本质上都是自定义了一个在无监督任务上的损失计算方法。我们重点讨论前两种方法,具体地:
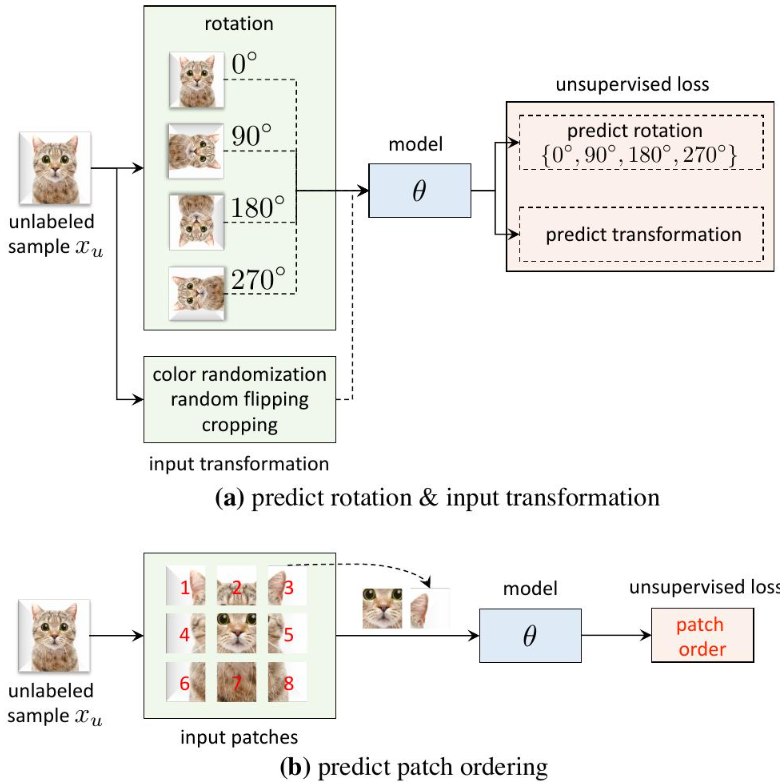
- 自监督学习 (Self-supervised Learning) 就是自己给图像打一个标签,然后就和监督学习一样了。当然这里的标签不是真实的语义标签,而是一些成本很低的低级语义标签,比如旋转度数、翻转情况、颜色变换等。通过让模型预测这些低级语义的标签,从而让模型可以很好的进行特征提取工作;
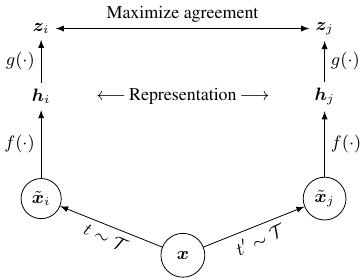
- 对比学习 (Contrastive Learning) 认为同一张图像的不同变换具有相同的特征表示。变换图像的成本相较于人工标注的成本就低很多了,基于这种思想,损失函数就被设计为:最小化同一张图片各种变换之间的差异,同时最大化不同图片的各种变换之间的差异。
MAE¶
掩码自编码器 (Masked Auto Encoder, MAE) 5 算自监督学习的一个实例。其实是一种很巧妙的想法,其自定义的标签是原始图像中的真实像素值,然后通过掩盖住真实图像的一部分,让模型最小化重构损失。这也被称为像素级的预训练方法。如下图所示:
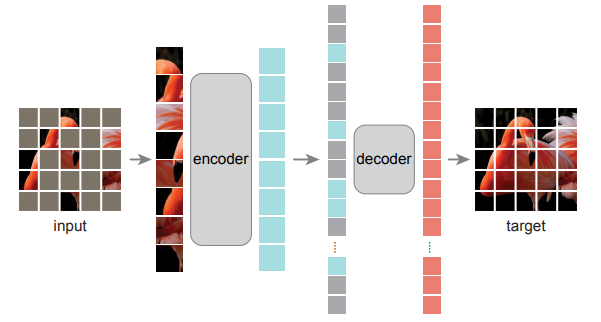
当然,还有实例级的预训练方法,即对整张图做一些变换,然后得到自定义的标签,比如旋转、翻转、切分等等。如下图所示:
SimCLR¶
SimCLR 6 采用了对比学习方法。假设一个 mini-batch 的大小为 \(N\),对于其中的每一张图片 \(X_i\),将其变换两次得到 \(\overset{\sim} X_{i1},\overset{\sim} X_{i2}\),然后最小化 \(\overset{\sim} X_{i1}\) 与 \(\overset{\sim} X_{i2}\) 之间的差异,从而让模型学习到所有图片的最佳特征表示。

CLIP¶
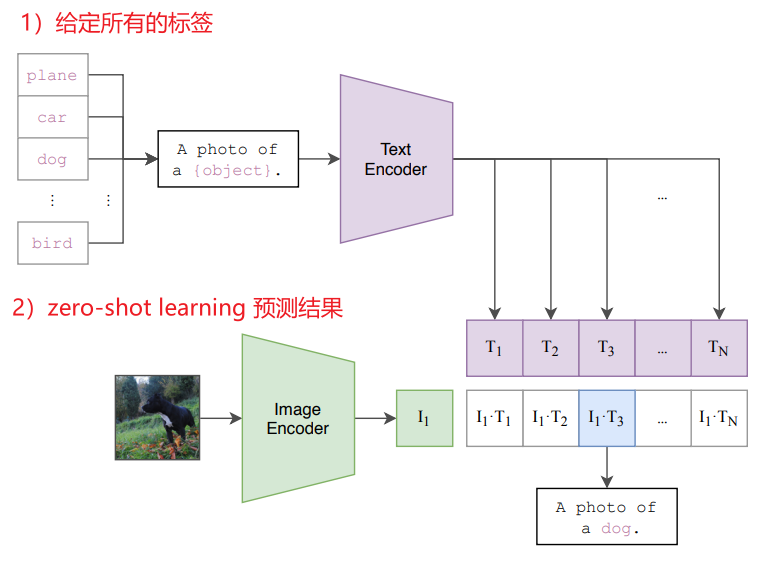
OpenAI 在 2021 年开源了一个模型,或者说是一种预训练方法,叫做 Contrastive Language-Image Pre-training,即赫赫有名的 CLIP 7 8。同样是对比学习,只不过现在对于一张图片 \(X_i\),与其对比的不再是变换的图像,而是一个对应的文本 \(T_i\)。预训练过程如下图所示:
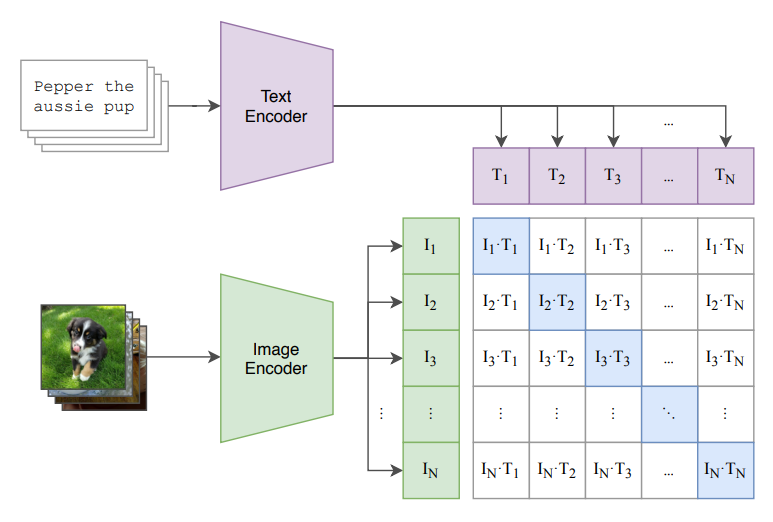
可以看到,算法思想很简单,就是把图文进行对比学习。假设一个 mini-batch 大小为 \(N\),那么学习准则就是最大化 \(N\) 对匹配图文的余弦相似度,同时最小化 \(N^2-N\) 对不匹配的图文的余弦相似度。牛就牛在数据规模很大,OpenAI 从网上爬了 4 亿对匹配的图文数据对。然后就是基于这么个预训练结果,开始在图像分类任务上刷各种 SOTA 了。比如可以在 zero-shot learning 的情况下媲美监督训练的 SOTA。
当然,基于预训练出来的 Image Encoder 和 Text Encoder 进行 zero-shot learning 时,需要进行一些基本设置。比如在下游的某个有标签的图像分类数据集上进行测试时,需要首先给 Text Encoder 所有的类别标签,然后才能通过 Image Encoder 在已知的所有类别标签上预测出一个概率最大的对应标签结果。
-
Semi-Supervised and Unsupervised Deep Visual Learning: A Survey - (arxiv.org) ↩↩
-
Mixmatch: A holistic approach to semi-supervised learning - (proceedings.neurips.cc) ↩
-
D. Chen et al., “Tri-net for semi-supervised deep learning,” in Proc. Int. Joint Conf.Artif. Intell., 2018, pp. 2014–2020. ↩
-
Masked Autoencoders Are Scalable Vision Learners - (openaccess.thecvf.com) ↩
-
A Simple Framework for Contrastive Learning of Visual Representations - (dl.acm.org) ↩
-
Learning Transferable Visual Models From Natural Language Supervision | OpenAI - (arxiv.org) ↩