动作识别
基本概念
动作识别定义
假设时序长度为 \(T\) 的视频表示为 \(X = x_1, x_2, \cdots , x_T\),其中 \(x_i\) 表示第 \(i\) 帧图像。定义动作标签集合 \(c\in C\),其中每个 \(c\) 表示一个特定的动作类别。
动作识别 (Action Recognition) 任务可以看作是一个分类问题,其目标是找到一个映射函数 \(f\),该函数将 \(X\) 映射到动作标签集合 \(C\) 中的一个标签:\(f: X \to C\)。
数据集

评价指标
Clip Hit@k:从视频中提取多个片段 (clip),每个片段独立预测,统计所有 clip 的 Top-k 准确率。
Video Hit@k:将同一个视频的多个 clip 的预测结果进行聚合,统计所有 video 的 Top-k 准确率。
*注:Top-k 表示模型输出 k 次的结果中是否存在正确答案,因此我们平时常说的准确率其实是 Top-1 指标。
早期做法
一种做法是将图像的特征融合为视频的特征 1 ,直接的融合方式可分为以下三种:
- 早期融合 (Early fusion)
- 晚期融合 (Late fusion)
- 缓慢融合 (Slow fusion)
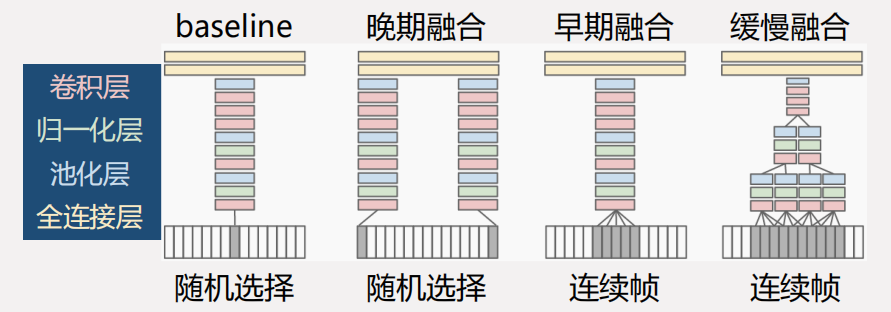
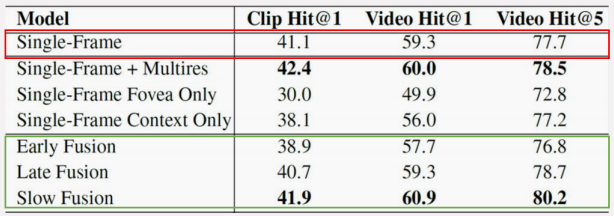
缓慢融合方式在网络内部逐渐融合相邻帧的信息,取得了最好的效果。但融合了时序信息的效果并没有显著优于基于静态图像的效果,说明基于 2D 卷积的网络难以有效提取运动信息。
引入光流的网络
为了让模型捕捉到不同帧之间的关系,需要引入物体运动的信息,光流就是物体运动的一种量化表示方式。
光流的定义
TODO
双流网络
为了让网络更好地利用运动信息,双流网络 (Two-stream convolutional network) 2 引入了光流 (Optical flow) 信息。


实验结果表明:
- 基于手工特征的 IDT 在当时取得了最高的准确率;
- 缓慢融合方式距离 IDT 差距明显;
- 双流网络的效果虽然弱于 IDT,但是充分验证了深度学习用于视频动作识别的可行性。
基于双流网络的改进
如何设计池化层以理解更长时序的动作。论文阅读 3。
如何融合双流信息以增强模型的性能。论文阅读 4。
如何设计网络使能够处理更长时序的视频:时序片段网络 (Temporal Segment Network, TSN) 5 将视频划分为不同的片段,然后综合各个片段的分类结果。
基于 3D 卷积的网络
光流信息的计算与存储开销极大,人们开始尝试使用 3D 卷积来完成动作识别任务。

C3D
C3D 6 直接将 VGG 的卷积操作从 \(3\times 3\) 拓展到了 \(3\times 3\times 3\),在 Sport-1M 数据集上进行训练。

特点:
- C3D 直接在 Sport-1M 数据集上训练,取得的效果要好于缓慢融合网络;
- C3D 在更大的数据集上预训练,再进行微调,则可以取得更好的效果;
- C3D 的训练时间非常长,难以继续拓展。

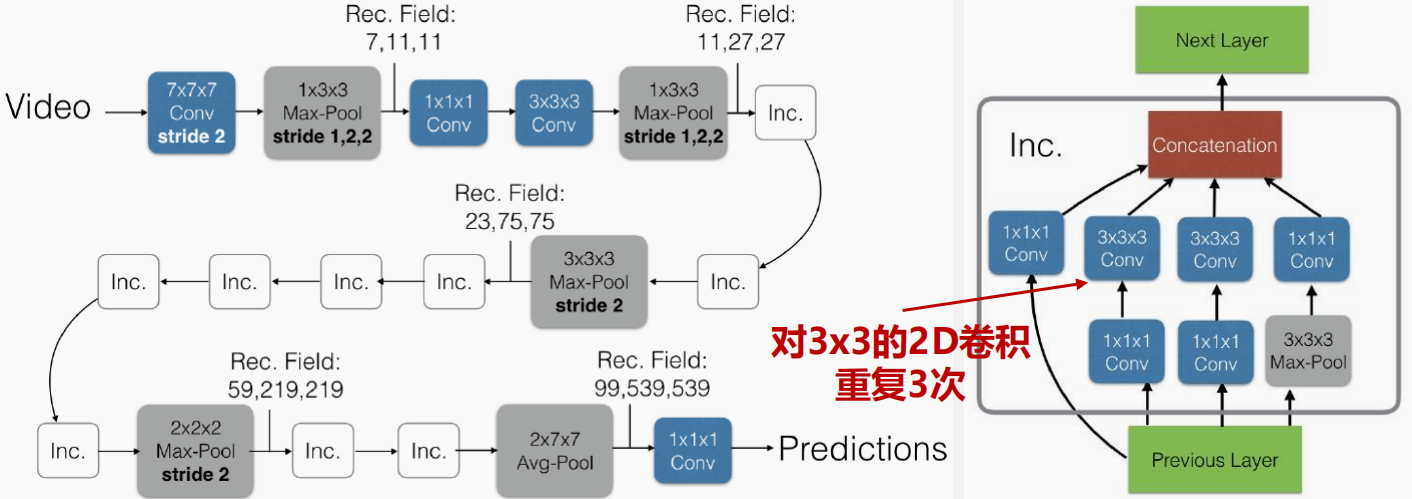
I3D
使用预训练模型初始化网络的参数可以增强模型的效果并降低训练难度,因此 I3D 7 提出了膨胀 3D 卷积 (Inflated 3D convolution)。

基于 Transformer 的网络
TimeSformer 8 是第一个尝试将 ViT 9 引入到动作识别任务的工作。如何将应用于 2D 图像的 ViT 迁移到视频领域的动作识别任务?
类似于之前的工作,TimeSformer 对于如何将 ViT 拓展到视频数据进行了大量的探索。



用 Transformer 的好处:
- Transformer 的全局建模能力使得相关模型能够更好地利用时序上下文信息,更易于应用到长时序的视频;
- Transformer 没有归纳偏置 (inductive),更易于拓展成多模态模型。
-
Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014: 1725-1732. ↩
-
Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[J]. Advances in neural information processing systems, 2014, 27. ↩
-
Yue-Hei Ng J, Hausknecht M, Vijayanarasimhan S, et al. Beyond short snippets: Deep networks for video classification//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 4694-4702. ↩
-
Feichtenhofer C, Pinz A, Zisserman A. Convolutional two-stream network fusion for video action recognition//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1933-1941. ↩
-
Wang L, Xiong Y, Wang Z, et al. Temporal segment networks: Towards good practices for deep action recognition[C]//European conference on computer vision. Springer, Cham, 2016: 20-36. ↩
-
Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 4489-4497. ↩
-
Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6299-6308. ↩
-
Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding?[C]//ICML. 2021, 2(3): 4. ↩
-
轻松理解 ViT(Vision Transformer) 原理及源码 | 000_error - (zhuanlan.zhihu.com) ↩